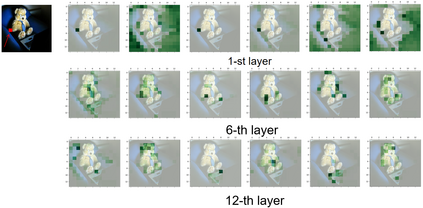
In this paper, we consider the image captioning task from a new sequence-to-sequence prediction perspective and propose Caption TransformeR (CPTR) which takes the sequentialized raw images as the input to Transformer. Compared to the "CNN+Transformer" design paradigm, our model can model global context at every encoder layer from the beginning and is totally convolution-free. Extensive experiments demonstrate the effectiveness of the proposed model and we surpass the conventional "CNN+Transformer" methods on the MSCOCO dataset. Besides, we provide detailed visualizations of the self-attention between patches in the encoder and the "words-to-patches" attention in the decoder thanks to the full Transformer architecture.
翻译:在本文中,我们从新的序列到序列的预测角度来考虑图像说明任务,并提议Caption TransformeR(CPTR),它将序列原始图像作为输入器输入到变异器中。与“CNN+ Transformex”的设计范式相比,我们的模型可以从一开始就在每一个编码层中模拟全球背景,并且完全没有进化。广泛的实验证明了所拟议的模型的有效性,我们超越了在 MCCO 数据集中的常规“CNN+ Transformex”方法。此外,我们提供了由于全变异器结构而使编码器中的补丁和解码器中的“字对字节”的注意力的详细可视化。