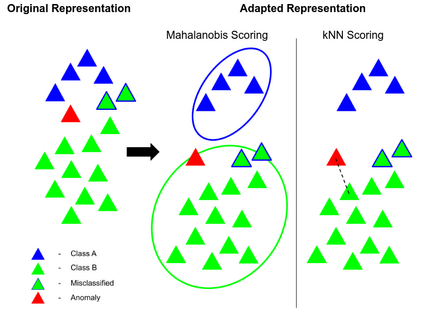
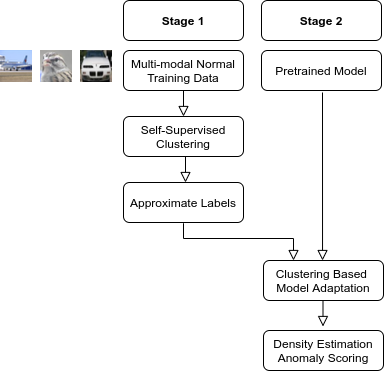
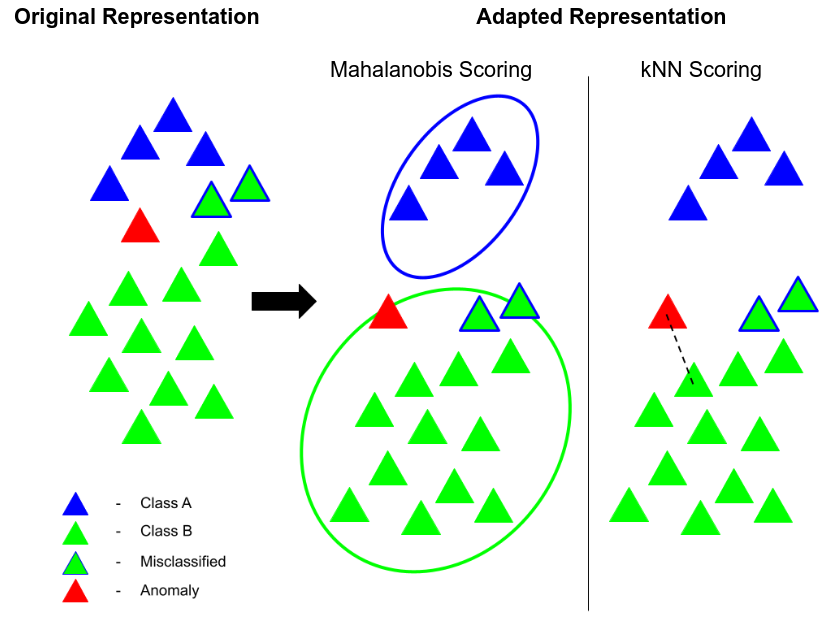
Anomaly detection methods identify samples that deviate from the normal behavior of the dataset. It is typically tackled either for training sets containing normal data from multiple labeled classes or a single unlabeled class. Current methods struggle when faced with training data consisting of multiple classes but no labels. In this work, we first discover that classifiers learned by self-supervised image clustering methods provide a strong baseline for anomaly detection on unlabeled multi-class datasets. Perhaps surprisingly, we find that initializing clustering methods with pre-trained features does not improve over their self-supervised counterparts. This is due to the phenomenon of catastrophic forgetting. Instead, we suggest a two stage approach. We first cluster images using self-supervised methods and obtain a cluster label for every image. We use the cluster labels as "pseudo supervision" for out-of-distribution (OOD) methods. Specifically, we finetune pretrained features on the task of classifying images by their cluster labels. We provide extensive analyses of our method and demonstrate the necessity of our two-stage approach. We evaluate it against the state-of-the-art self-supervised and pretrained methods and demonstrate superior performance.
翻译:异常的检测方法发现样本与数据集的正常行为不同,通常用于包含来自多标签类或单一无标签类的正常数据的训练组,通常用于处理包含来自多标签类或单一无标签类的正常数据的训练组。当面临由多类但无标签的培训数据时,目前的方法会挣扎。在这项工作中,我们首先发现,通过自我监督图像群集方法学习的分类者为在未标签的多类数据集中检测异常提供了强有力的基准。也许令人惊讶的是,我们发现,采用预先训练的特性的初始集成方法不会比自控的对应方法改进。这是灾难性的遗忘现象造成的。相反,我们建议采取两个阶段方法。我们首先使用自我监督的方法集成图像,并获得每个图像的集成标签。我们使用集成标签作为分配外(OOOD)方法的“假监制”的“假象监督” 。具体地说,我们细化了按其群集标签对图像分类任务的预先训练特点。我们提供了我们的方法的广泛分析,并展示了我们两阶段方法的必要性。我们用的是对照状态的高级性表现和训练方法来评估。