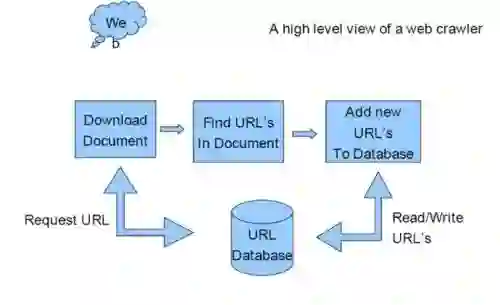
Web resources are increasingly interactive, resulting in resources that are increasingly difficult to archive. The archival difficulty is based on the use of client-side technologies (e.g., JavaScript) to change the client-side state of a representation after it has initially loaded. We refer to these representations as deferred representations. We can better archive deferred representations using tools like headless browsing clients. We use 10,000 seed Universal Resource Identifiers (URIs) to explore the impact of including PhantomJS -- a headless browsing tool -- into the crawling process by comparing the performance of wget (the baseline), PhantomJS, and Heritrix. Heritrix crawled 2.065 URIs per second, 12.15 times faster than PhantomJS and 2.4 times faster than wget. However, PhantomJS discovered 531,484 URIs, 1.75 times more than Heritrix and 4.11 times more than wget. To take advantage of the performance benefits of Heritrix and the URI discovery of PhantomJS, we recommend a tiered crawling strategy in which a classifier predicts whether a representation will be deferred or not, and only resources with deferred representations are crawled with PhantomJS while resources without deferred representations are crawled with Heritrix. We show that this approach is 5.2 times faster than using only PhantomJS and creates a frontier (set of URIs to be crawled) 1.8 times larger than using only Heritrix.
翻译:网络资源日益互动,导致越来越难以存档的资源。档案的困难在于使用客户端技术(如JavaScript)在初始装货后改变代表的客户端状态。我们将这些代表称为延迟代表。我们可以用无头浏览客户等工具更好地归档推迟的表述。我们使用10 000种种子通用资源标识器(URIs)来探索将幽灵JS(一个无头浏览工具)纳入爬行过程的影响,通过比较wget(基线)、PhantomJS和Heritrix的性能(如JavaScript)和客户端技术(如JavaScript)的性能。HeritomJS的爬行率为2.065 URIs(每秒)、12.15倍于PhantomJS和2.4倍于 wget。然而,PhantomJS发现了5314 URIs,比HIRx(海利克斯)的性能效益和URIJS的发现速度。我们建议采用一个更深的爬行战略,而我们只使用一个不延式的图像的图像代表将显示,而我们只是一个更延迟的螺路路路代表。