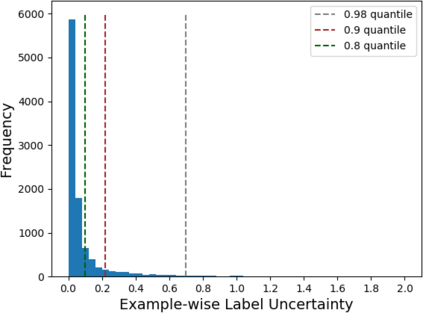
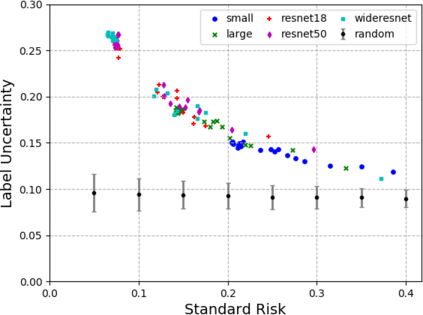
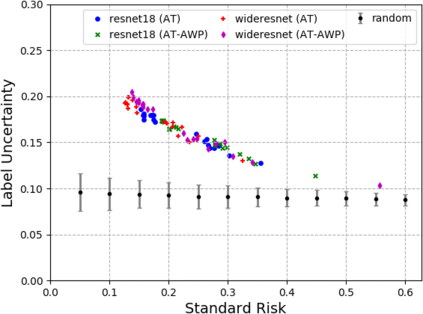
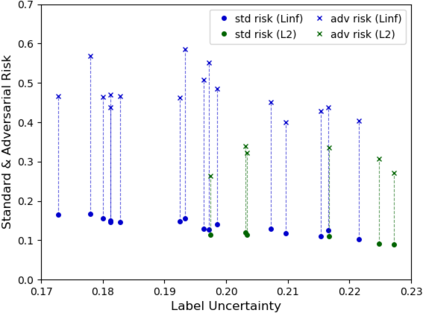
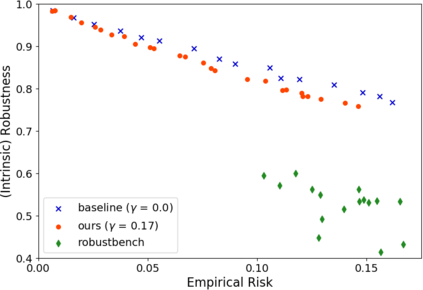
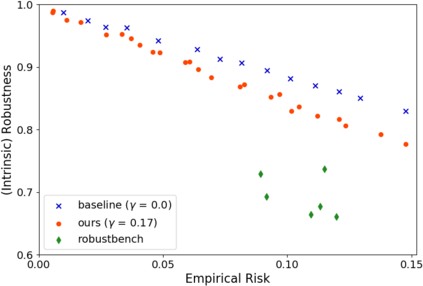
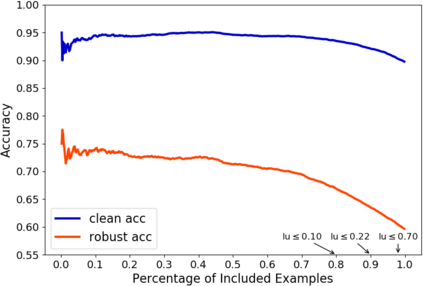
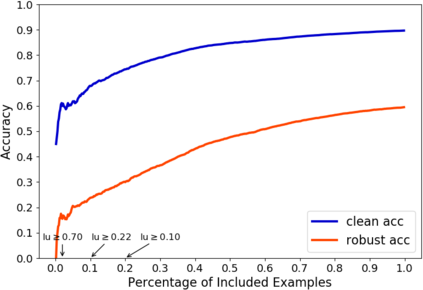
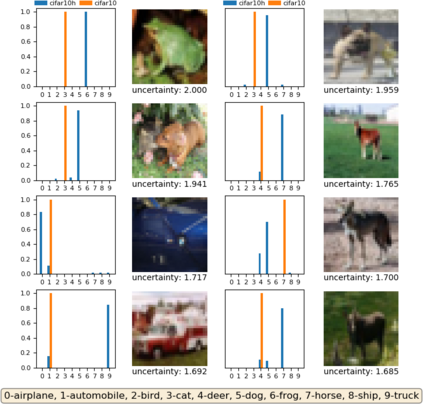
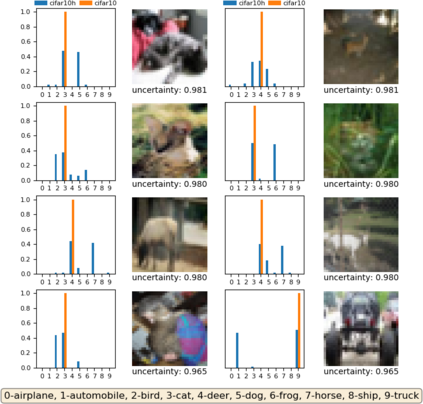
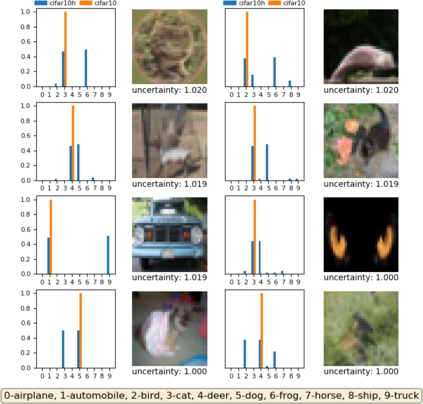
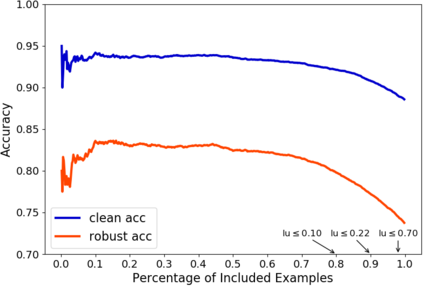
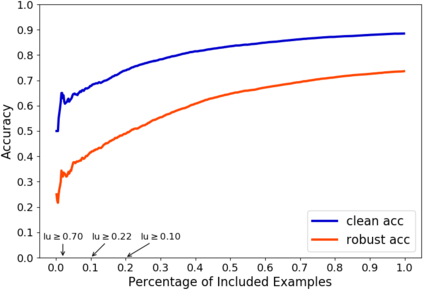
A fundamental question in adversarial machine learning is whether a robust classifier exists for a given task. A line of research has made progress towards this goal by studying concentration of measure, but without considering data labels. We argue that the standard concentration fails to fully characterize the intrinsic robustness of a classification problem, since it ignores data labels which are essential to any classification task. Building on a novel definition of label uncertainty, we empirically demonstrate that error regions induced by state-of-the-art models tend to have much higher label uncertainty compared with randomly-selected subsets. This observation motivates us to adapt a concentration estimation algorithm to account for label uncertainty, resulting in more accurate intrinsic robustness measures for benchmark image classification problems. We further provide empirical evidence showing that adding an abstain option for classifiers based on label uncertainty can help improve both the clean and robust accuracies of models.
翻译:对抗性机器学习中的一个基本问题是,是否存在一个强大的分类器来完成某项任务。一线研究通过研究计量的集中程度,但没有考虑数据标签,从而在实现这一目标方面取得了进展。我们争辩说,标准集中度未能充分说明分类问题的内在稳健性,因为它忽略了任何分类任务所必需的数据标签。基于标签不确定性的新定义,我们从经验上证明,由最先进的模型引起的误差区域与随机选择的子集相比,其标签不确定性往往要高得多。这一观察促使我们调整集中估计算法,以考虑到标签不确定性,从而导致为基准图像分类问题制定更准确的内在稳健性衡量标准。我们还提供了经验证据,表明基于标签不确定性的分类者增加弃权选项有助于改进模型的清洁和稳健的精度。