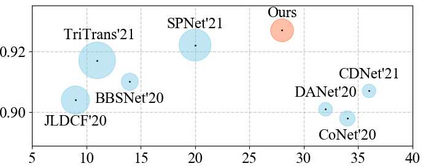
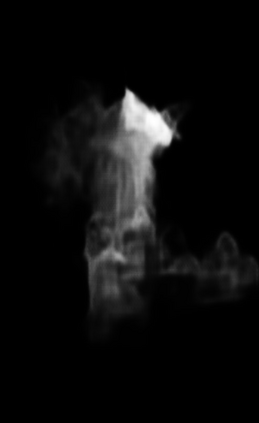
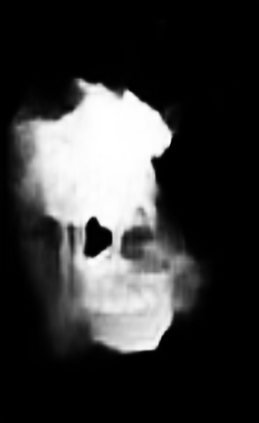
Efficiently exploiting multi-modal inputs for accurate RGB-D saliency detection is a topic of high interest. Most existing works leverage cross-modal interactions to fuse the two streams of RGB-D for intermediate features' enhancement. In this process, a practical aspect of the low quality of the available depths has not been fully considered yet. In this work, we aim for RGB-D saliency detection that is robust to the low-quality depths which primarily appear in two forms: inaccuracy due to noise and the misalignment to RGB. To this end, we propose a robust RGB-D fusion method that benefits from (1) layer-wise, and (2) trident spatial, attention mechanisms. On the one hand, layer-wise attention (LWA) learns the trade-off between early and late fusion of RGB and depth features, depending upon the depth accuracy. On the other hand, trident spatial attention (TSA) aggregates the features from a wider spatial context to address the depth misalignment problem. The proposed LWA and TSA mechanisms allow us to efficiently exploit the multi-modal inputs for saliency detection while being robust against low-quality depths. Our experiments on five benchmark datasets demonstrate that the proposed fusion method performs consistently better than the state-of-the-art fusion alternatives.
翻译:为准确的 RGB-D 显性探测高效利用多质量投入,这是一个引起高度关注的议题。大多数现有工作都利用跨模式互动,将RGB-D的两流RGB-D连接起来,以提升中间特性。在这一过程中,尚未充分考虑现有深度质量低的一个实际方面。在这项工作中,我们的目标是通过RGB-D显性检测,这种检测对于主要以两种形式出现的低质量深度具有很强的力度:噪音和与RGB的不匹配造成的不准确性。为此,我们提议采用一种强大的RGB-D融合方法,从(1) 层之间和(2) 三进制空间、注意机制中获益。一方面,分层关注(LWA)了解RGB和深度特征早期和后期融合之间的利弊。另一方面,三分层空间关注将各种特征从更广泛的空间角度综合起来,以解决深度不匹配问题。为此,拟议的LWA和TSA机制使我们能够有效地利用多模式的深度投入,用于(分层和分层的空间)空间检测,而不是以稳健的、稳健的基化方法,同时展示我们拟议的五度基准级的深度探测。