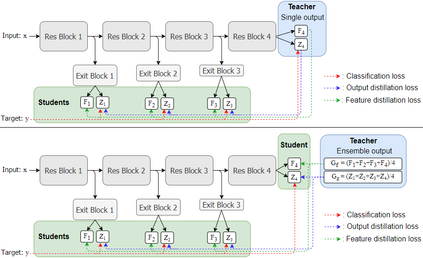
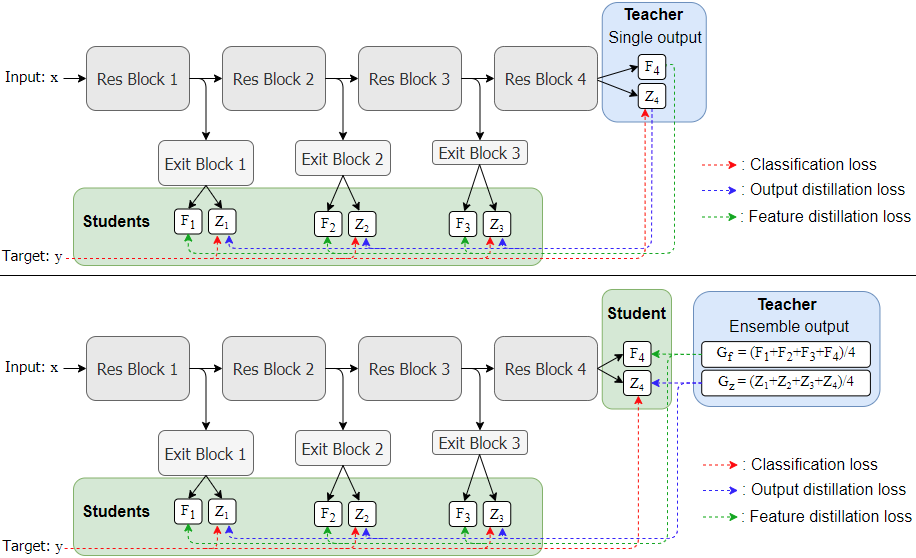
This paper proposes a novel knowledge distillation-based learning method to improve the classification performance of convolutional neural networks (CNNs) without a pre-trained teacher network, called exit-ensemble distillation. Our method exploits the multi-exit architecture that adds auxiliary classifiers (called exits) in the middle of a conventional CNN, through which early inference results can be obtained. The idea of our method is to train the network using the ensemble of the exits as the distillation target, which greatly improves the classification performance of the overall network. Our method suggests a new paradigm of knowledge distillation; unlike the conventional notion of distillation where teachers only teach students, we show that students can also help other students and even the teacher to learn better. Experimental results demonstrate that our method achieves significant improvement of classification performance on various popular CNN architectures (VGG, ResNet, ResNeXt, WideResNet, etc.). Furthermore, the proposed method can expedite the convergence of learning with improved stability. Our code will be available on Github.
翻译:本文提出一种新的基于知识蒸馏的学习方法,以提高未经事先培训的师资网络的进化神经网络(CNNs)的分类性能。我们的方法利用了在常规CNN中添加辅助分类器(所谓的退出)的多输出结构,通过这一结构可以取得早期推论结果。我们的方法的构想是利用退出的组合作为蒸馏目标来培训网络,这大大改进了整个网络的分类性能。我们的方法提出了新的知识蒸馏模式;不同于传统的蒸馏概念,即教师只教学生的蒸馏模式,我们表明学生也可以帮助其他学生甚至教师学习更好的。实验结果表明,我们的方法大大改进了各种受欢迎的CNN结构(VGG、ResNet、ResNeXt、WideResNet等)的分类性能。此外,拟议的方法可以加快学习与更稳定的融合。我们的代码将在Github上公布。