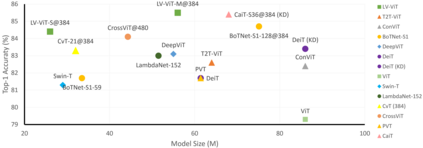
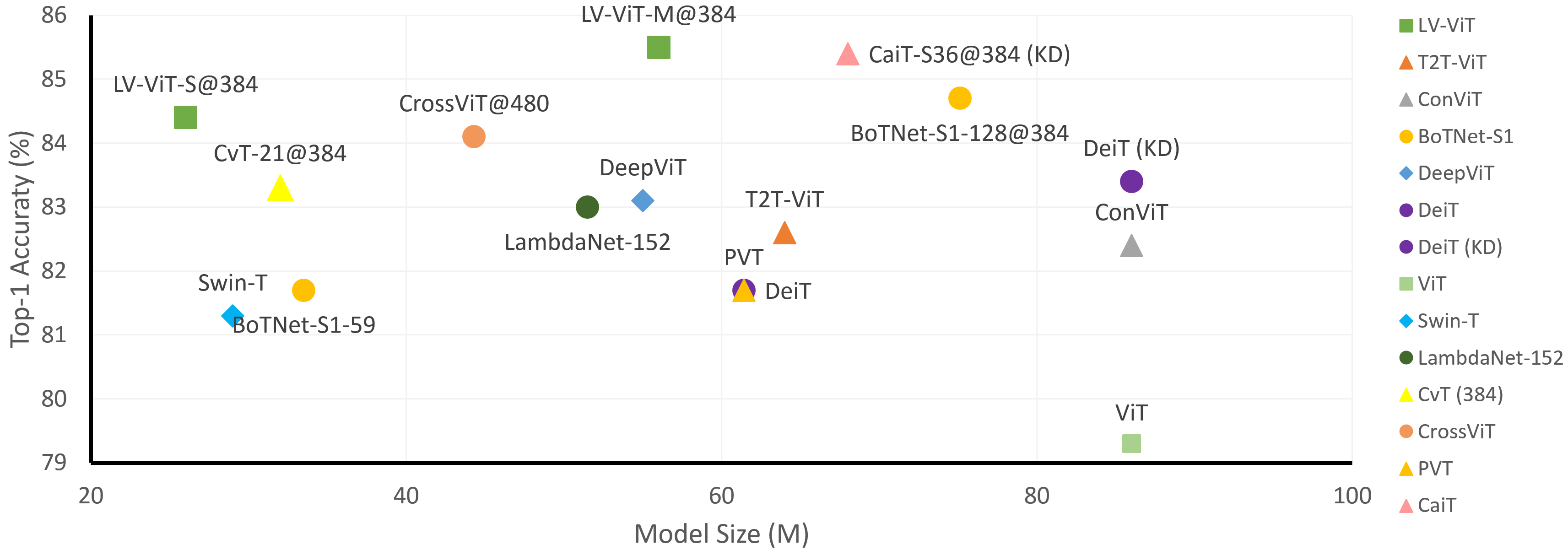
This paper provides a strong baseline for vision transformers on the ImageNet classification task. While recent vision transformers have demonstrated promising results in ImageNet classification, their performance still lags behind powerful convolutional neural networks (CNNs) with approximately the same model size. In this work, instead of describing a novel transformer architecture, we explore the potential of vision transformers in ImageNet classification by developing a bag of training techniques. We show that by slightly tuning the structure of vision transformers and introducing token labeling -- a new training objective, our models are able to achieve better results than the CNN counterparts and other transformer-based classification models with similar amount of training parameters and computations. Taking a vision transformer with 26M learnable parameters as an example, we can achieve an 84.4% Top-1 accuracy on ImageNet. When the model size is scaled up to 56M/150M, the result can be further increased to 85.4%/86.2% without extra data. We hope this study could provide researchers with useful techniques to train powerful vision transformers. Our code and all the training details will be made publicly available at https://github.com/zihangJiang/TokenLabeling.
翻译:本文为图像网络分类任务中的视觉变压器提供了一个强有力的基准。 尽管最近的视觉变压器在图像网络分类中展示了令人乐观的结果, 但其性能仍然落后于具有大致相同模型大小的强大革命性神经网络(CNNs ) 。 在这项工作中,我们没有描述一个新的变压器结构,而是通过开发一袋培训技术来探索图像网络分类中的视觉变压器的潜力。 我们通过对视觉变压器的结构进行微调并引入象征性标签 -- -- 一个新的培训目标 -- -- 我们的模型能够取得比CNN对等和其他具有类似培训参数和计算量的以变压器为基础的分类模型更好的结果。 我们的代码和所有培训细节将在https://github.com/ziangJian/Tokenling上公开提供。 当模型规模扩大到56M/150M时,结果可以进一步提高到85.4%/86.2%, 而没有额外数据。 我们希望这项研究可以为研究人员提供有用的技术来培训强大的视觉变压器。 我们的代码和所有培训细节将在https://gthhubub.com/ziangJian/TokeangLanging/Tokening/Tokening/Tokening