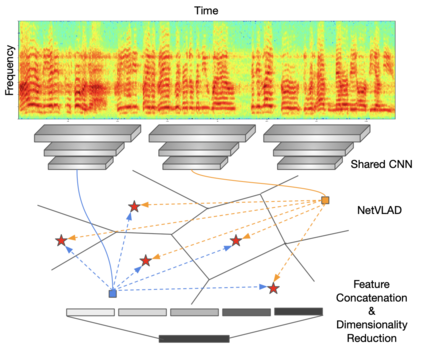
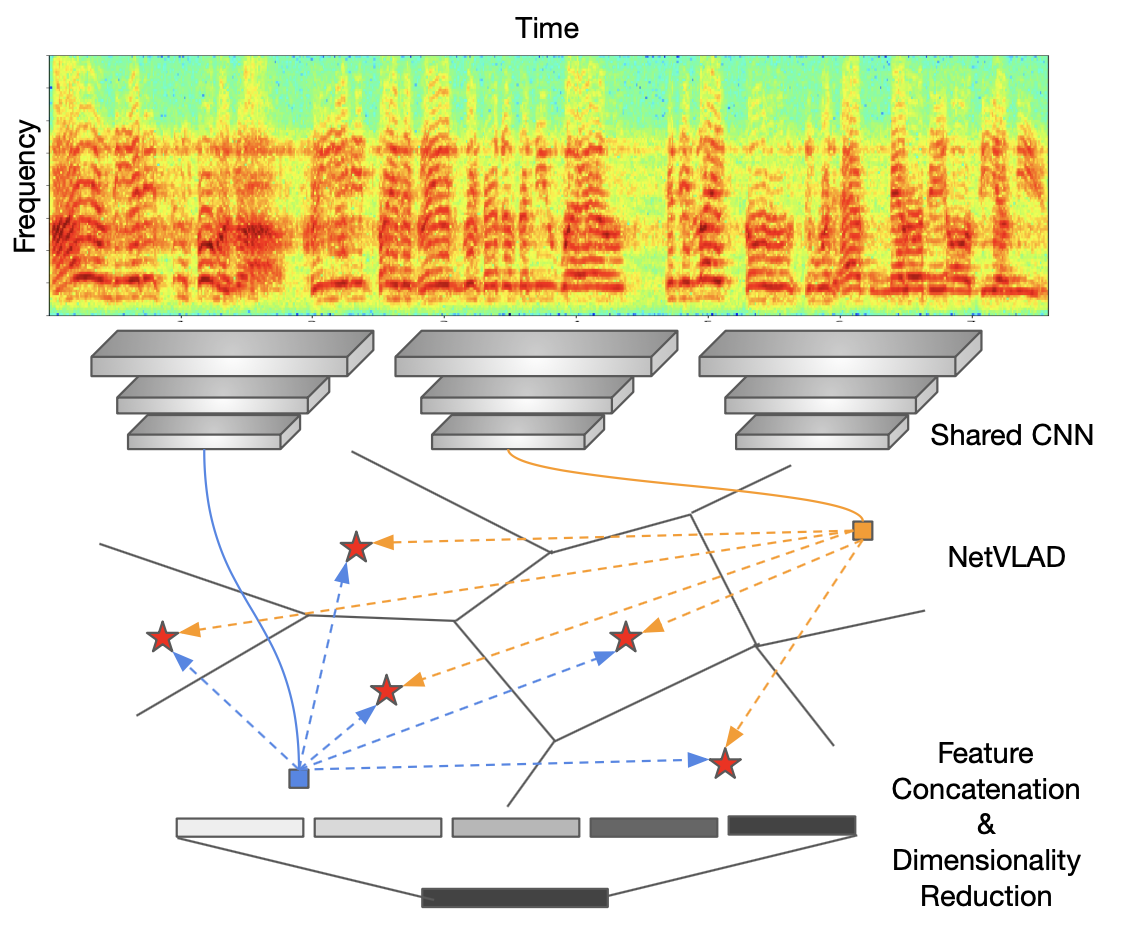
The objective of this paper is speaker recognition "in the wild"-where utterances may be of variable length and also contain irrelevant signals. Crucial elements in the design of deep networks for this task are the type of trunk (frame level) network, and the method of temporal aggregation. We propose a powerful speaker recognition deep network, using a "thin-ResNet" trunk architecture, and a dictionary-based NetVLAD or GhostVLAD layer to aggregate features across time, that can be trained end-to-end. We show that our network achieves state of the art performance by a significant margin on the VoxCeleb1 test set for speaker recognition, whilst requiring fewer parameters than previous methods. We also investigate the effect of utterance length on performance, and conclude that for "in the wild" data, a longer length is beneficial.
翻译:本文的目标是“野生”语句识别“在野外”语句可能长度不一,而且含有不相关的信号。设计这一任务的深网络的关键要素是主干(框架水平)网络的类型和时间汇总方法。我们建议使用“Thin-ResNet” 中继结构以及基于字典的NetVLAD或GholdVLAD层来汇总可以经过培训的、可以最终到终端的时空特征,建立一个强大的深层语句识别网络。我们表明,我们的网络通过在VoxCeleb1号测试中为语音识别设定一个显著的差幅,实现了最新性能,同时要求的参数要少于以往的方法。我们还调查了长语句对性能的影响,并得出结论认为,对于“野生”数据来说,更长的长度是有益的。