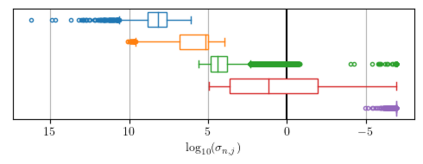
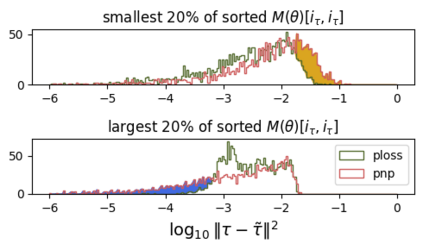
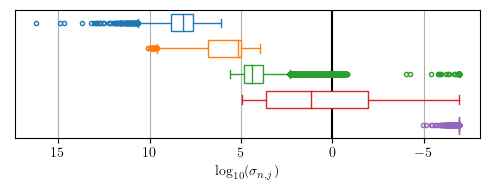
Sound matching algorithms seek to approximate a target waveform by parametric audio synthesis. Deep neural networks have achieved promising results in matching sustained harmonic tones. However, the task is more challenging when targets are nonstationary and inharmonic, e.g., percussion. We attribute this problem to the inadequacy of loss function. On one hand, mean square error in the parametric domain, known as "P-loss", is simple and fast but fails to accommodate the differing perceptual significance of each parameter. On the other hand, mean square error in the spectrotemporal domain, known as "spectral loss", is perceptually motivated and serves in differentiable digital signal processing (DDSP). Yet, spectral loss is a poor predictor of pitch intervals and its gradient may be computationally expensive; hence a slow convergence. Against this conundrum, we present Perceptual-Neural-Physical loss (PNP). PNP is the optimal quadratic approximation of spectral loss while being as fast as P-loss during training. We instantiate PNP with physical modeling synthesis as decoder and joint time-frequency scattering transform (JTFS) as spectral representation. We demonstrate its potential on matching synthetic drum sounds in comparison with other loss functions.
翻译:声音匹配算法试图通过模拟声学合成来接近目标波形。 深神经网络在匹配持续调音音调方面已经取得了令人乐观的结果。 但是, 当目标不是静止的, 和调和的, 例如震荡等, 任务就更具挑战性。 我们将此问题归咎于损失功能的不足。 一方面, 参数域中被称为“ P- loss” 的中位方差差是简单而快速的, 但却无法适应每个参数的不同感知意义。 另一方面, 光谱时空域中被称为“ 光谱损失” 的中位差差率差是感性的, 具有感知性动力, 并且用于不同的数字信号处理( DSP ) 。 然而, 光谱损失是投射间隔预测力差的低, 其梯度可能计算成本高昂; 因此, 缓慢的趋同。 与此交错, 我们呈现着感知觉- 神经- PNPP 是光谱损失的最佳二次近点近似值, 同时与P- 损耗损速度一样快。 我们即用物理模拟合成合成合成合成的PNPPPPPPPPPPP, 作为解合成合成合成合成合成,, 以解变换成其他时光谱。</s>