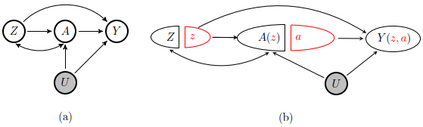
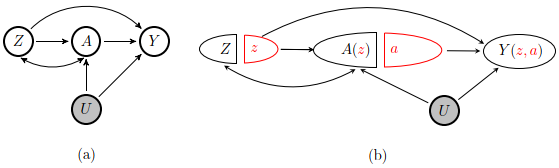
Instrumental variable methods have been widely used to identify causal effects in the presence of unmeasured confounding. A key identification condition known as the exclusion restriction states that the instrument cannot have a direct effect on the outcome which is not mediated by the exposure in view. In the health and social sciences, such an assumption is often not credible. To address this concern, we consider identification conditions of the population average treatment effect with an invalid instrumental variable which does not satisfy the exclusion restriction, and derive the efficient influence function targeting the identifying functional under a nonparametric observed data model. We propose a novel multiply robust locally efficient estimator of the average treatment effect that is consistent in the union of multiple parametric nuisance models, as well as a multiply debiased machine learning estimator for which the nuisance parameters are estimated using generic machine learning methods, that effectively exploit various forms of linear or nonlinear structured sparsity in the nuisance parameter space. When one cannot be confident that any of these machine learners is consistent at sufficiently fast rates to ensure $\surd{n}$-consistency for the average treatment effect, we introduce a new criteria for selective machine learning which leverages the multiple robustness property in order to ensure small bias. The proposed methods are illustrated through extensive simulations and a data analysis evaluating the causal effect of 401(k) participation on savings.
翻译:一种被称为排除限制的关键识别条件指出,该工具不能对未受接触影响的结果产生直接的影响。在卫生和社会科学中,这种假设往往不可信。为了解决这一关切,我们考虑确定人口平均治疗效果的条件,使用一种不能满足排斥限制的无效工具变量,并得出针对在非参数观测数据模型下识别功能的有效影响功能。我们提议采用一个新的方法,增加一个对当地平均治疗效果的强大有效估计器,这种效果与多重偏差骚扰模型的结合一致,以及一个多重偏差机器学习估计值,对此,使用通用机器学习方法估计的干扰参数,有效地利用各种线性或非线性结构化的偏差,从而满足不了排除限制,并得出针对在非参数空间下识别功能的有效影响功能。当人们不能确信这些机器学习者中的任何比例都足够快,以确保平均治疗效果的当地有效估计值一致,以及平均治疗效果的偏差机器学习估计值乘以倍增的机器学习估计值。1 我们采用一种新的选择性模型,通过多种分析方法,确保持续的参与率分析。