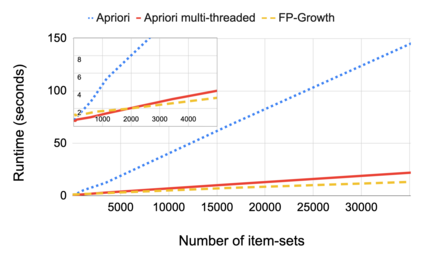
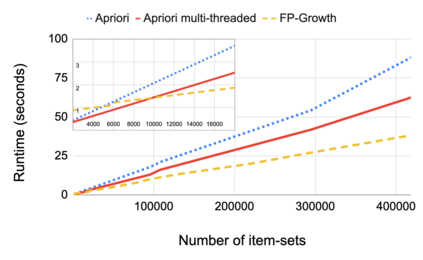
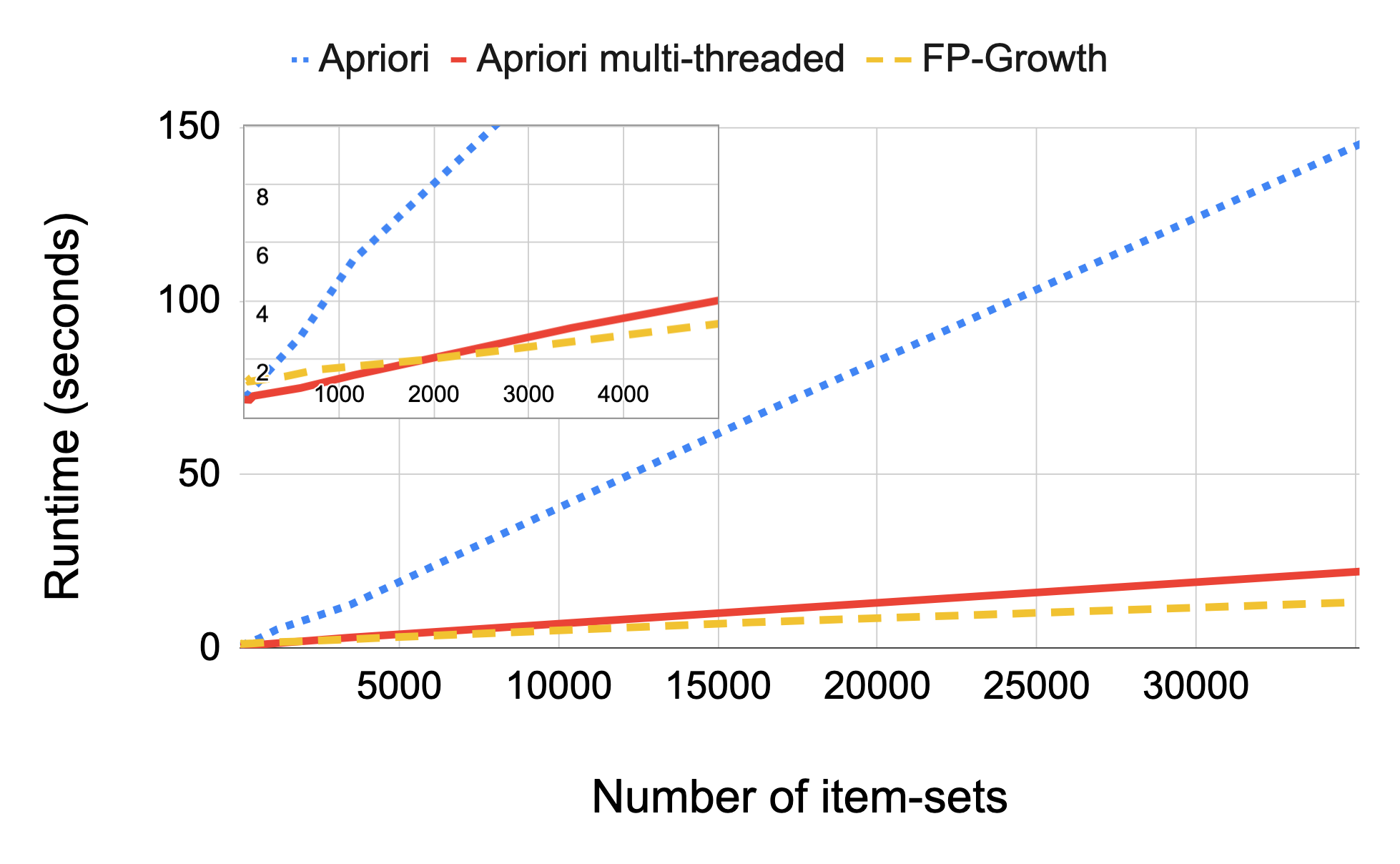
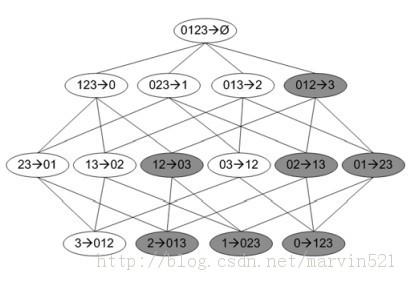
Root cause analysis in a large-scale production environment is challenging due to the complexity of services running across global data centers. Due to the distributed nature of a large-scale system, the various hardware, software, and tooling logs are often maintained separately, making it difficult to review the logs jointly for detecting issues. Another challenge in reviewing the logs for identifying issues is the scale - there could easily be millions of entities, each with hundreds of features. In this paper we present a fast dimensional analysis framework that automates the root cause analysis on structured logs with improved scalability. We first explore item-sets, i.e. a group of feature values, that could identify groups of samples with sufficient support for the target failures using the Apriori algorithm and a subsequent improvement, FP-Growth. These algorithms were designed for frequent item-set mining and association rule learning over transactional databases. After applying them on structured logs, we select the item-sets that are most unique to the target failures based on lift. With the use of a large-scale real-time database, we propose pre- and post-processing techniques and parallelism to further speed up the analysis. We have successfully rolled out this approach for root cause investigation purposes in a large-scale infrastructure. We also present the setup and results from multiple production use-cases in this paper.
翻译:大规模生产环境中的根源分析由于全球数据中心服务的复杂性而具有挑战性。由于大规模系统分布性,各种硬件、软件和工具日志往往分开保存,因此难以共同审查日志以发现问题。审查用于查明问题的日志的另一个挑战是规模----可能很容易有数百万个实体,每个实体都有数百个特征。在本文件中,我们提出了一个快速的维基分析框架,将根源分析自动化到结构化日志上,提高可缩放性。我们首先探索项目集,即一组特性值,以便利用Ariorori算法和随后的改进,确定对目标失败给予足够支持的样本群。这些算法是为频繁的物品定置采矿和交易数据库的关联规则学习设计的。在对结构化日志应用后,我们选择了对升级目标失败最独特的项目集。我们先和后期数据库使用大型实时数据库,我们建议从大规模处理技术和平行研究中找出样本组群,然后用这一大规模的基础分析。我们从大规模研究中成功地运用了这一基础分析。