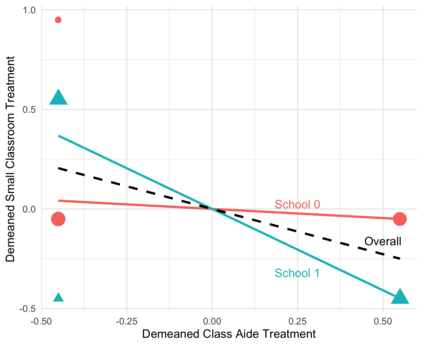
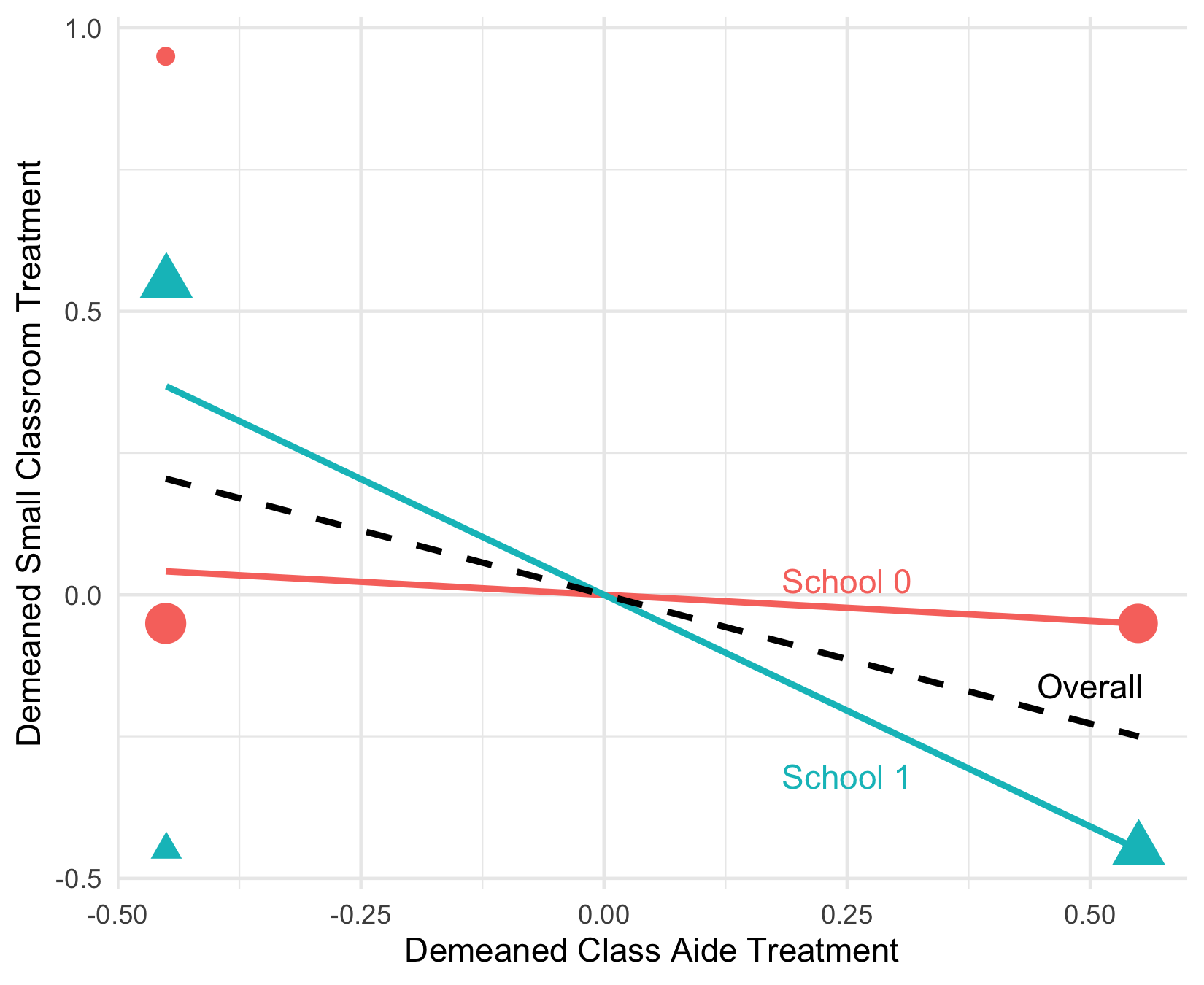
We study the interpretation of regressions with multiple treatments and flexible controls. Such regressions are often used to analyze stratified randomized control trials with multiple intervention arms, to estimate value-added (for, e.g., teachers) with observational data, and to leverage the quasi-random assignment of decision-makers (e.g. bail judges). We show that these regressions generally fail to estimate convex averages of heterogeneous treatment effects, even when the treatments are conditionally randomly assigned and the controls are sufficiently flexible to avoid omitted variables bias. Instead, estimates of each treatment's effects are generally contaminated by a non-convex average of the effects of other treatments. Thus, recent concerns about heterogeneity-induced bias in regressions leveraging potential outcome restrictions (e.g. parallel trends assumptions) also arise with "design-based" identification strategies. We discuss solutions to the contamination bias and propose a new class of efficient estimators of weighted average effects that avoid bias. In a re-analysis of the Project STAR trial, we find minimal bias because treatment effect heterogeneity is largely idiosyncratic. But sizeable contamination bias arises when effect heterogeneity becomes correlated with treatment propensity scores.
翻译:我们研究的是以多种治疗和灵活控制方法的回归解释。这种回归常常用来分析以多种干预武器进行分层随机控制试验,用观察数据来估计增值(例如教师),利用决策者(例如保释法官)的准随机分配。我们表明,这些回归通常无法估计不同治疗效果的共性平均值,即使治疗是有条件随机分配的,控制足够灵活,以避免忽略的变数偏差。相反,对每种治疗效果的估计通常受到其他治疗效果非共性平均值的污染。因此,最近人们担心,在利用潜在结果限制的回归(例如平行趋势假设)中出现异性引起的偏差(例如,平行趋势假设),也与“基于指定”的识别战略有关。我们讨论污染偏差的解决方案,并提出避免偏差的加权平均效果的有效估计新类别。在重新分析项目STAR试验时,我们发现最低限度的偏差,因为治疗效果的异性是非共性,在偏差性与偏差性之间产生巨大的偏差性。但是,当偏差性与偏差性发生时,则会产生巨大的偏差性。