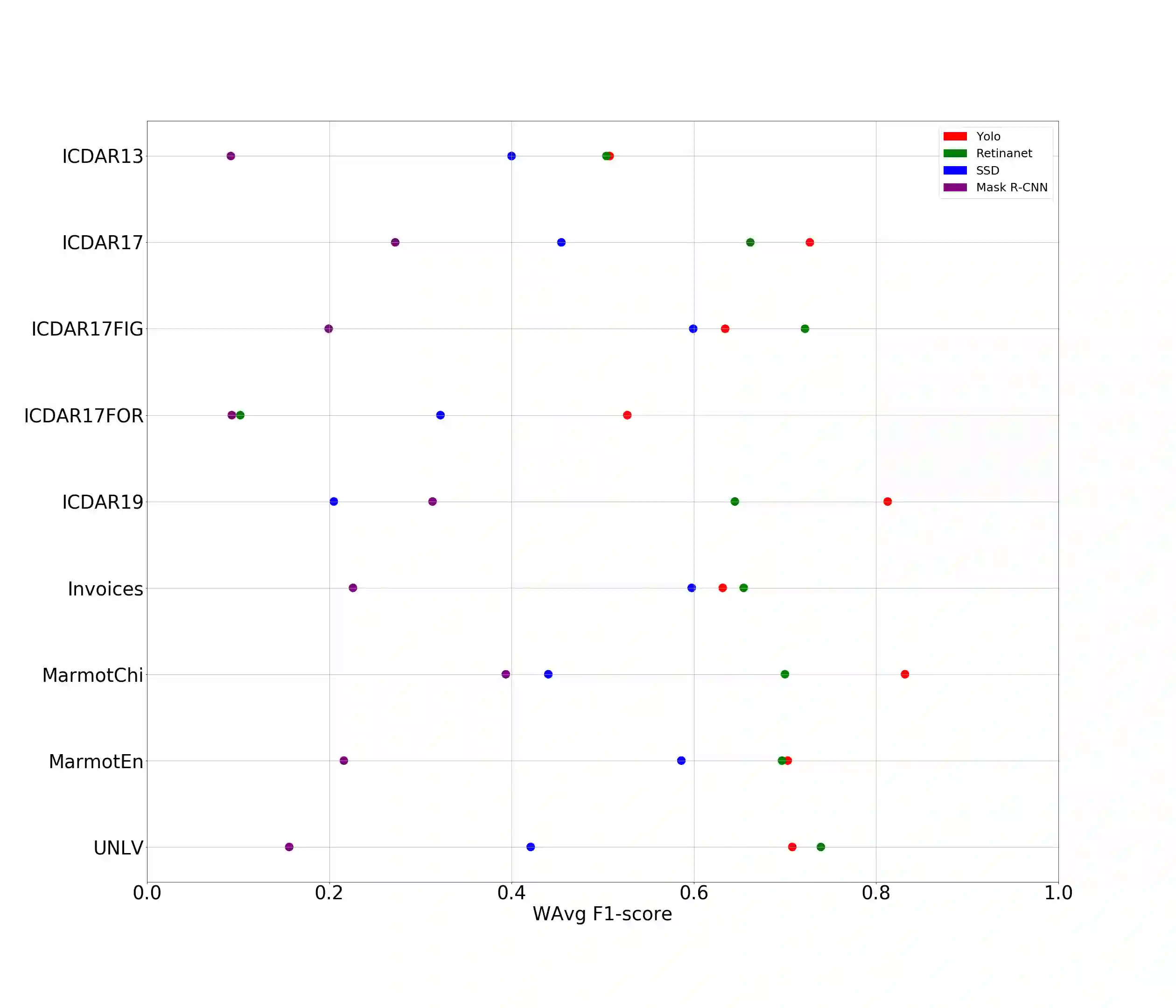
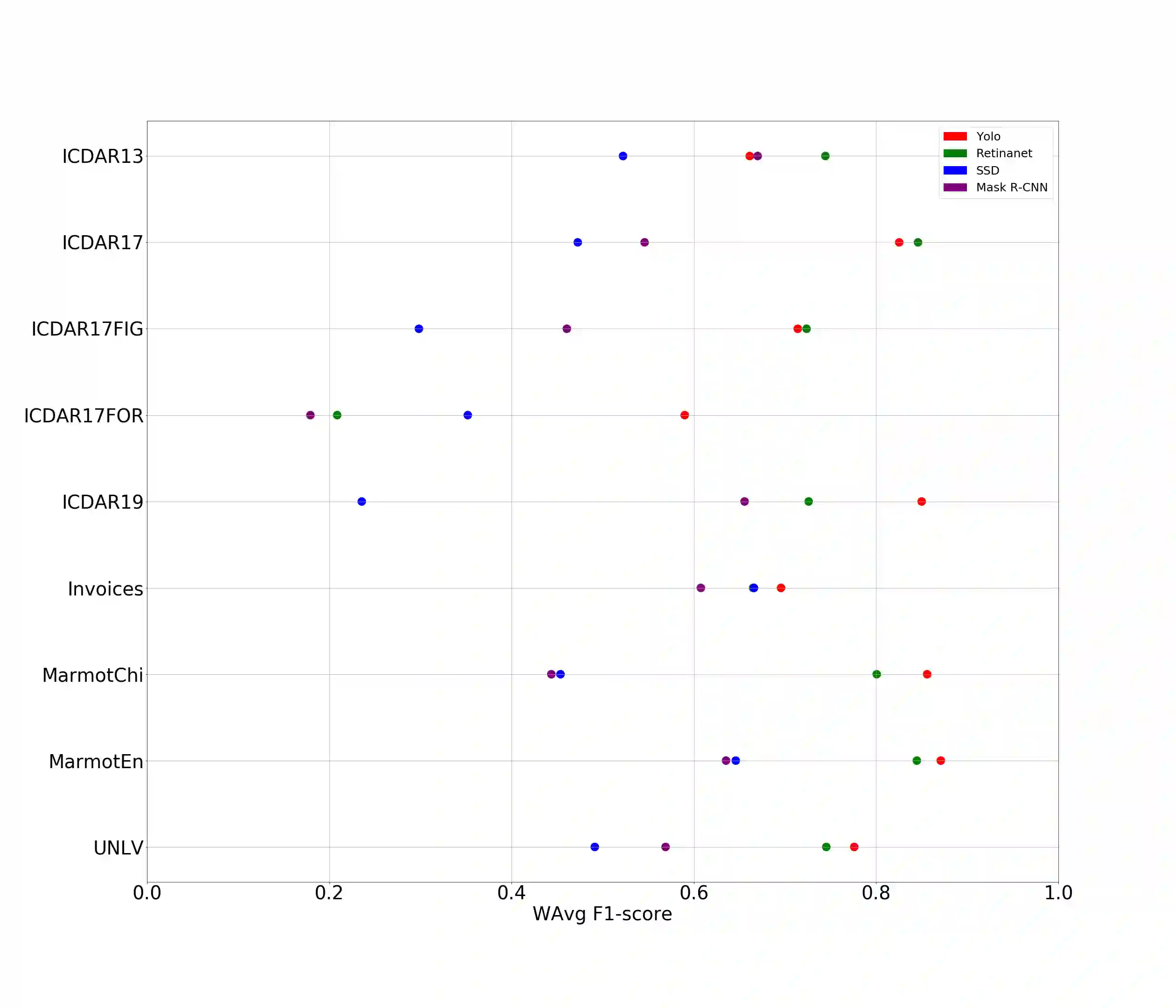
A correct localisation of tables in a document is instrumental for determining their structure and extracting their contents; therefore, table detection is a key step in table understanding. Nowadays, the most successful methods for table detection in document images employ deep learning algorithms; and, particularly, a technique known as fine-tuning. In this context, such a technique exports the knowledge acquired to detect objects in natural images to detect tables in document images. However, there is only a vague relation between natural and document images, and fine-tuning works better when there is a close relation between the source and target task. In this paper, we show that it is more beneficial to employ fine-tuning from a closer domain. To this aim, we train different object detection algorithms (namely, Mask R-CNN, RetinaNet, SSD and YOLO) using the TableBank dataset (a dataset of images of academic documents designed for table detection and recognition), and fine-tune them for several heterogeneous table detection datasets. Using this approach, we considerably improve the accuracy of the detection models fine-tuned from natural images (in mean a 17%, and, in the best case, up to a 60%).
翻译:文档中的表格正确定位有助于确定其结构和提取内容; 因此, 表格检测是表格理解中的一个关键步骤。 如今, 文档图像中最成功的表格检测方法采用深层次学习算法; 特别是称为微调的技术。 在这方面, 这种技术输出在自然图像中探测天体以探测文件图像表格的知识。 然而, 自然图像和文件图像之间只有模糊的关系, 微调在源和目标任务之间有密切关系时效果更好。 在本文中, 我们表明从更近的域进行微调更有益。 为此, 我们培训不同的对象检测算法( 即, Mask R- CNN、 RetinanNet、 SSD 和 YOLO), 使用表班克数据集( 用于表格检测和识别的学术文件的数据集), 并微调这些图案用于若干混杂的表格检测数据集。 使用这种方法, 我们大大提高了从自然图像中微调的探测模型的准确性( 意为17%, 最佳情况下为60 % ) 。