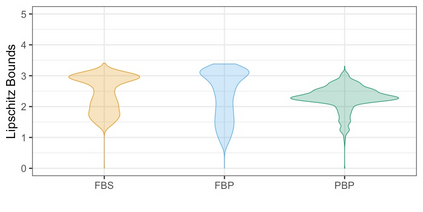
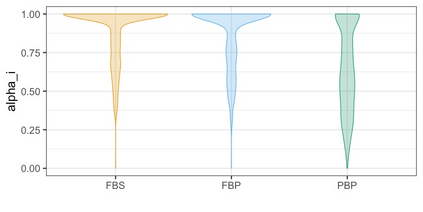
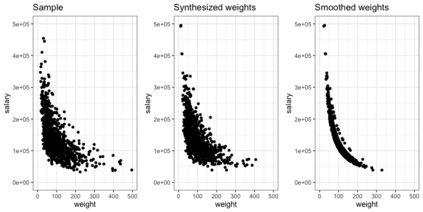
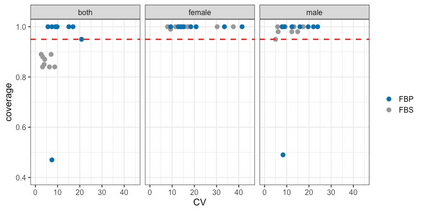
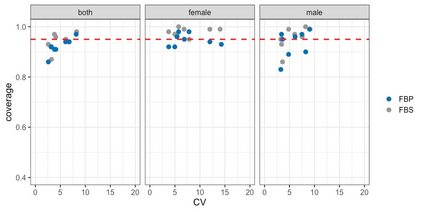
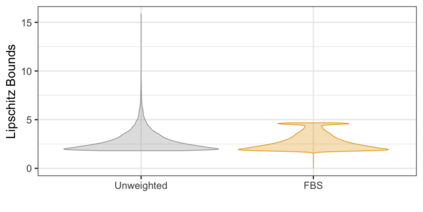
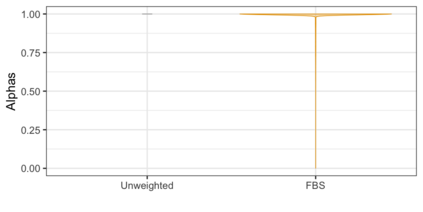
We propose three synthetic microdata approaches to generate private tabular survey data products for public release. We adapt a disclosure risk based-weighted pseudo posterior mechanism to survey data with a focus on producing tabular products under a formal privacy guarantee. Two of our approaches synthesize the observed sample distribution of the outcome and survey weights, jointly, such that both quantities together possess a probabilistic differential privacy guarantee. The privacy-protected outcome and sampling weights are used to construct tabular cell estimates and associated standard errors to correct for survey sampling bias. The third approach synthesizes the population distribution from the observed sample under a pseudo posterior construction that treats survey sampling weights as fixed to correct the sample likelihood to approximate that for the population. Each by-record sampling weight in the pseudo posterior is, in turn, multiplied by the associated privacy, risk-based weight for that record to create a composite pseudo posterior mechanism that both corrects for survey bias and provides a privacy guarantee for the observed sample. Through a simulation study and a real data application to the Survey of Doctorate Recipients public use file, we demonstrate that our three microdata synthesis approaches to construct tabular products provide superior utility preservation as compared to the additive-noise approach of the Laplace Mechanism. Moreover, all our approaches allow the release of microdata to the public, enabling additional analyses at no extra privacy cost.
翻译:我们建议采用三种综合微观数据方法,以生成供公众发行的私人表格调查数据产品; 我们采用一种基于披露风险的加权假后表层机制,以调查数据,重点是在正式隐私保障下生产表格产品; 我们采用两种方法,将观察到的结果和调查重量的样本分布合并在一起,使这两个数量加在一起,具有概率差异隐私权保障; 使用隐私保护的结果和抽样权重来构建表格细胞估计和相关标准差错,以纠正调查抽样偏差; 采用第三种方法,将所观察到的样本的人口分布综合到一个假后层结构中,将抽样权重作为固定的处理,以纠正抽样可能性,从而纠正对人口估计值的抽样; 我们采用两种方法,将所观察到的抽样权重合并成一份样本,以纠正对结果和调查权重的对比; 通过模拟研究和实际数据应用,我们的三个微观数据综合方法,将模拟抽样权标定了抽样权,以纠正抽样权的抽样权重,反过来以相关隐私和风险加权权重乘该记录,以创建综合假造价工具,使公共保密性数据升级法得以更新。