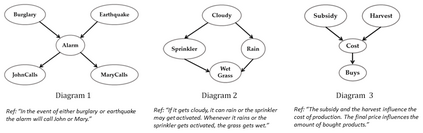
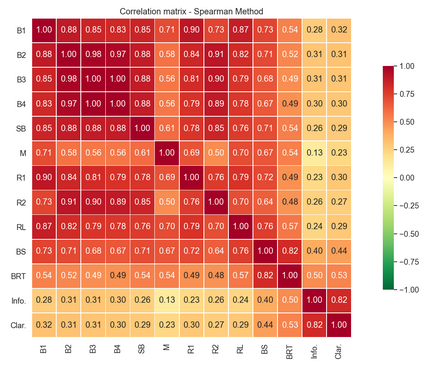
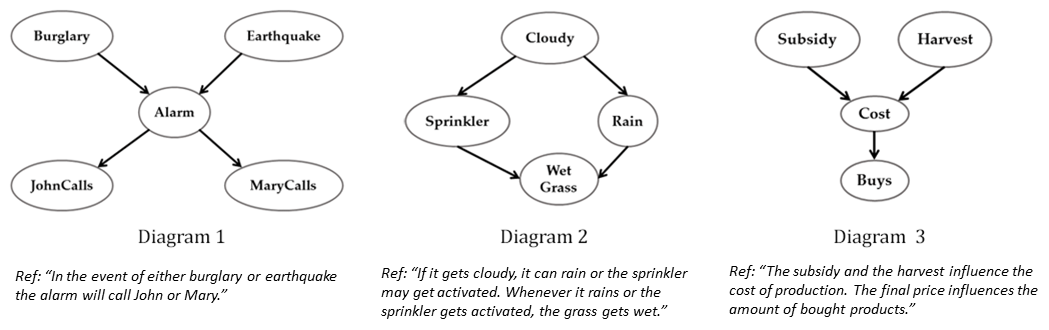
As transparency becomes key for robotics and AI, it will be necessary to evaluate the methods through which transparency is provided, including automatically generated natural language (NL) explanations. Here, we explore parallels between the generation of such explanations and the much-studied field of evaluation of Natural Language Generation (NLG). Specifically, we investigate which of the NLG evaluation measures map well to explanations. We present the ExBAN corpus: a crowd-sourced corpus of NL explanations for Bayesian Networks. We run correlations comparing human subjective ratings with NLG automatic measures. We find that embedding-based automatic NLG evaluation methods, such as BERTScore and BLEURT, have a higher correlation with human ratings, compared to word-overlap metrics, such as BLEU and ROUGE. This work has implications for Explainable AI and transparent robotic and autonomous systems.
翻译:随着透明度成为机器人和AI的关键,有必要评估提供透明度的方法,包括自动生成的自然语言(NL)解释。在这里,我们探讨此类解释的产生与大量研究的自然语言生成评价领域(NLG)之间的平行之处。具体地说,我们调查了NLG评价措施中哪些措施可以很好地解释。我们介绍了ExBANPRO:为Bayesian网络提供的大量来源的NL解释材料。我们运行了将人类主观评级与NLG自动措施进行比较的关联。我们发现,嵌入的自动NLG评价方法,如BERTScore和BLEURT,与LEU和ROUGE等多字指标相比,与人类评级的相关性更高。这项工作对可解释的AI以及透明的机器人和自主系统都有影响。