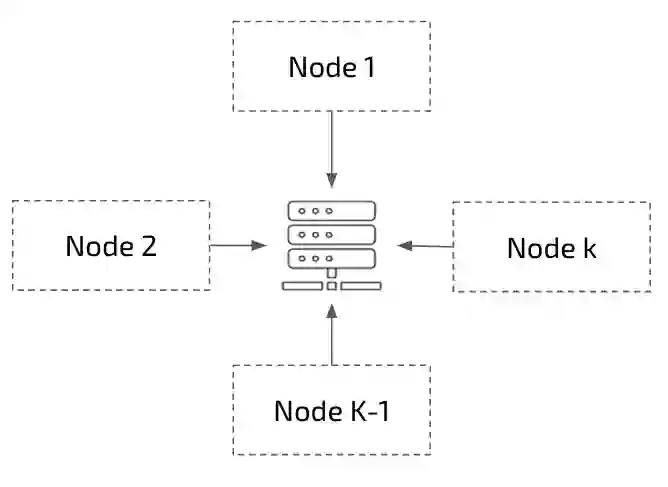
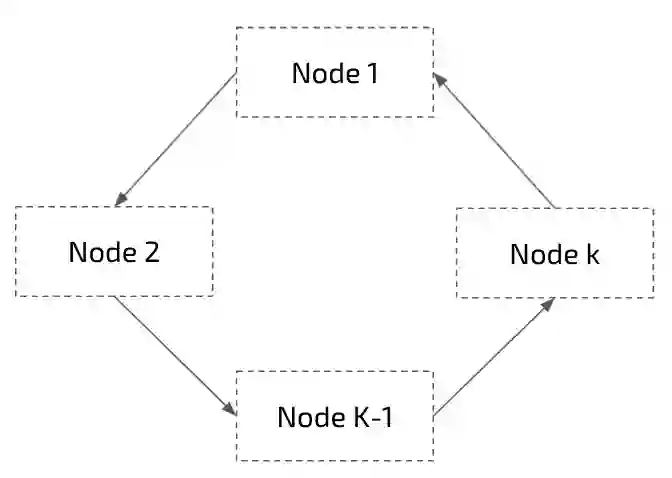
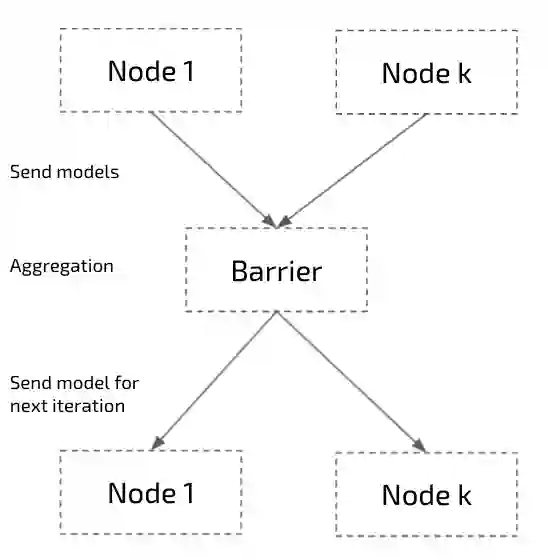
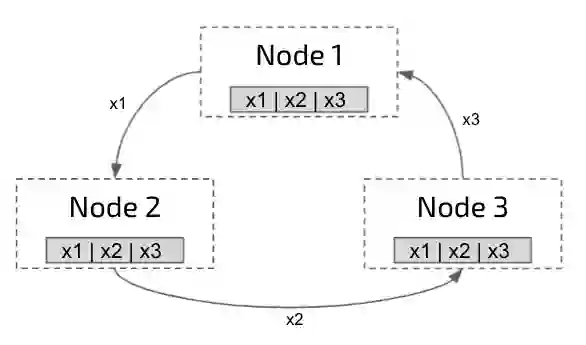
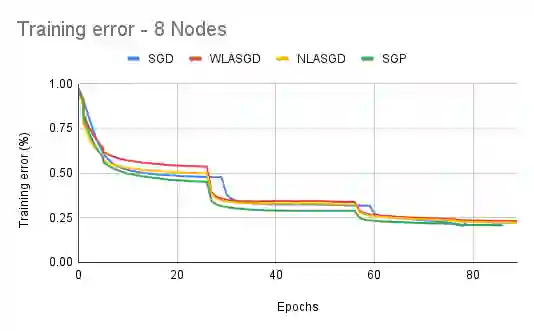
Distributed training algorithms of deep neural networks show impressive convergence speedup properties on very large problems. However, they inherently suffer from communication related slowdowns and communication topology becomes a crucial design choice. Common approaches supported by most machine learning frameworks are: 1) Synchronous decentralized algorithms relying on a peer-to-peer All Reduce topology that is sensitive to stragglers and communication delays. 2) Asynchronous centralised algorithms with a server based topology that is prone to communication bottleneck. Researchers also suggested asynchronous decentralized algorithms designed to avoid the bottleneck and speedup training, however, those commonly use inexact sparse averaging that may lead to a degradation in accuracy. In this paper, we propose Local Asynchronous SGD (LASGD), an asynchronous decentralized algorithm that relies on All Reduce for model synchronization. We empirically validate LASGD's performance on image classification tasks on the ImageNet dataset. Our experiments demonstrate that LASGD accelerates training compared to SGD and state of the art gossip based approaches.
翻译:深神经网络的分布式培训算法显示,在非常大的问题上,它们具有令人印象深刻的趋同速度加速特性,然而,它们本身就受到通信相关减速的影响,而通信地形学则成为关键的设计选择。大多数机器学习框架所支持的共同方法有:(1) 依赖对等对等分散式算法的同步分散式算法,这种算法对分流器和通信延迟十分敏感。(2) 以基于服务器、容易造成通信瓶颈的地形学为主的非同步中央化算法。研究人员还提出,为了避免瓶颈和加速培训,通常使用的分散式算法,这种算法通常不精密,可能导致准确性下降。在本文中,我们提议使用局部分散式的分散式算法(LASGD ), 这是一种依赖全速分散式的分散式算法, 用于模型同步。我们从经验上验证了LASGD在图像网数据集上对图像分类任务的表现。我们的实验表明,LASGD加速了与SGD相比培训的速度和基于艺术八的状态。