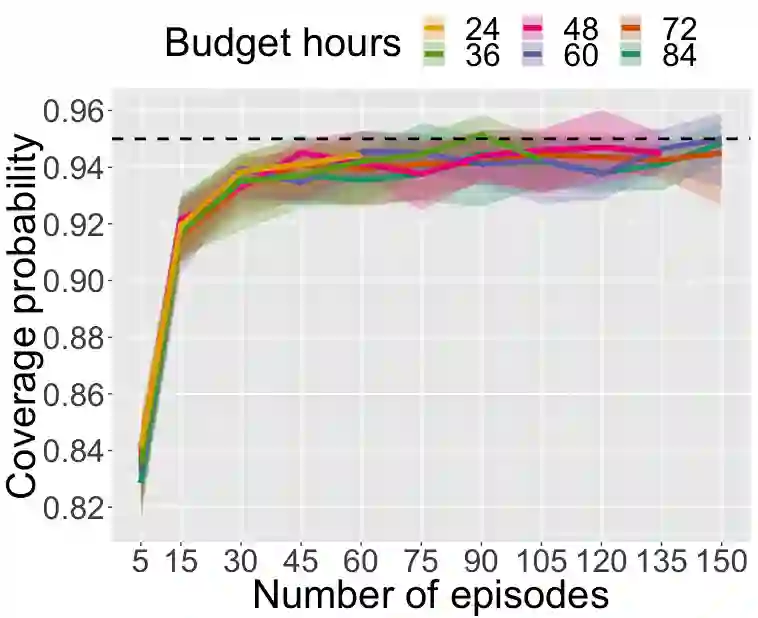
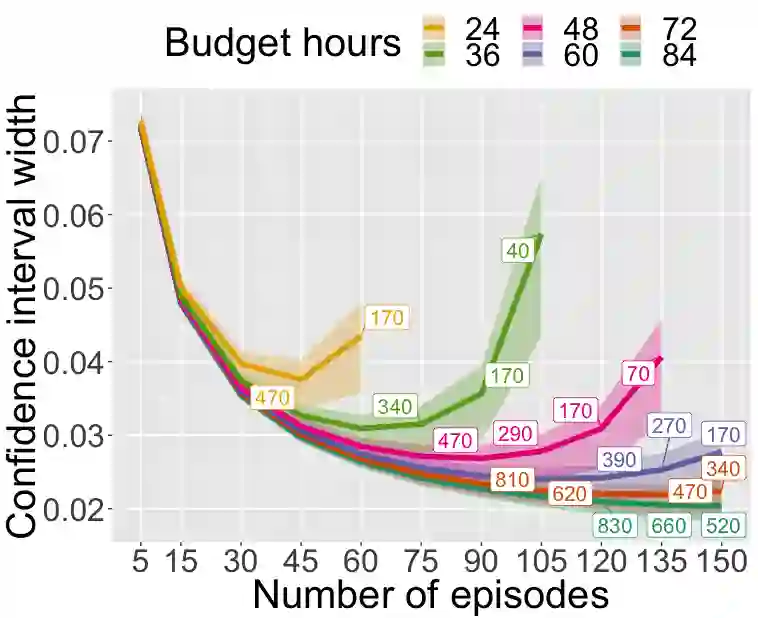
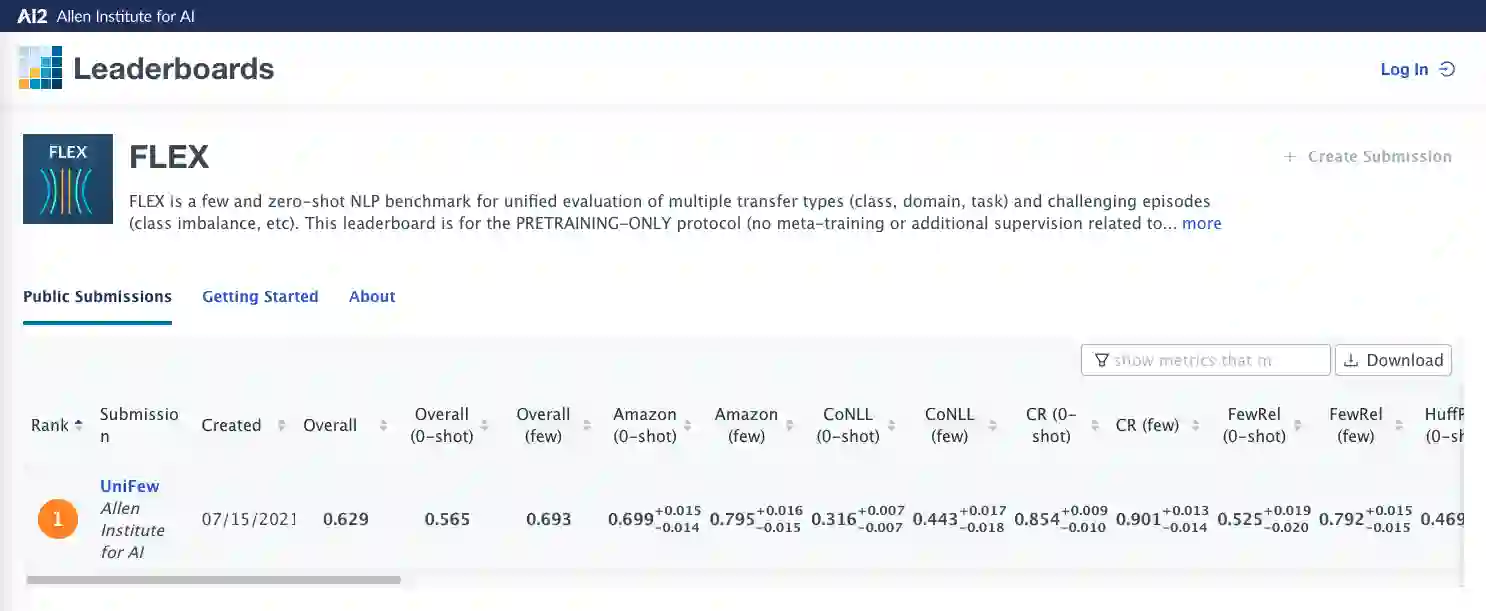
Few-shot NLP research is highly active, yet conducted in disjoint research threads with evaluation suites that lack challenging-yet-realistic testing setups and fail to employ careful experimental design. Consequently, the community does not know which techniques perform best or even if they outperform simple baselines. In response, we formulate the FLEX Principles, a set of requirements and best practices for unified, rigorous, valid, and cost-sensitive few-shot NLP evaluation. These principles include Sample Size Design, a novel approach to benchmark design that optimizes statistical accuracy and precision while keeping evaluation costs manageable. Following the principles, we release the FLEX benchmark, which includes four few-shot transfer settings, zero-shot evaluation, and a public leaderboard that covers diverse NLP tasks. In addition, we present UniFew, a prompt-based model for few-shot learning that unifies pretraining and finetuning prompt formats, eschewing complex machinery of recent prompt-based approaches in adapting downstream task formats to language model pretraining objectives. We demonstrate that despite simplicity, UniFew achieves results competitive with both popular meta-learning and prompt-based approaches.
翻译:微弱的NLP研究非常活跃,但是在与缺乏富有挑战性的现实测试设置和没有采用仔细实验设计的评价套件脱节的研究线索中进行,因此,社区不知道哪些技术最有效,即使它们优于简单的基线,也不知道哪些技术优于简单的基准。作为回应,我们制定了FLEX原则,一套统一、严格、有效、成本敏感的少见的NLP评价要求和最佳做法。这些原则包括抽样规模设计,这是衡量设计基准设计的新办法,在保持评价成本的同时,优化统计准确性和精确性。按照这些原则,我们公布了FLEX基准,其中包括四个短发的转移设置、零发评价以及一个涵盖各种NLP任务的公共领导板。此外,我们介绍了UniFew,一个快速的、基于几发式学习的模型,该模型整合了快速格式的预培训和微调,筛选了最近采用快速方法使下游任务格式适应语言模式培训前目标的复杂机制。我们证明,尽管简洁,UFew取得了与流行的元学习和快速方法的竞争性。