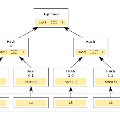
Merkle trees have become a widely successful cryptographic data structure. Enabling a vast variety of applications from checking for inconsistencies in databases like Dynamo to essential tools like Git to large scale distributed systems like Bitcoin and other blockchains. There have also been various versions of Merkle trees like Jellyfish Merkle Trees and Sparse Merkle Trees designed for different applications. However, one key drawback of all these Merkle trees is that with a large data set the cost of computing the tree increases significantly, moreover insert operations on a single leaf require re-building the entire tree. For certain use cases building the tree this way is acceptable, however in environments where compute time needs to be as low as possible and where data is processed in parallel, we are presented with a need for asynchronous computation. This paper proposes a solution where given a batch of data that has to be processed concurrently, a Merkle Tree can be constructed from the batch asynchronously without needing to recalculate the tree for every insert.
翻译:暂无翻译