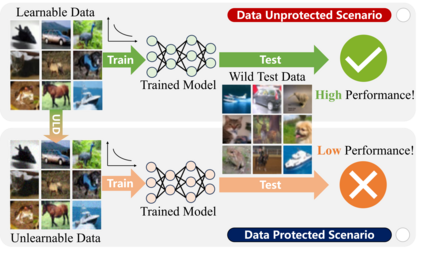
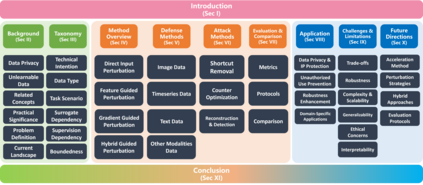
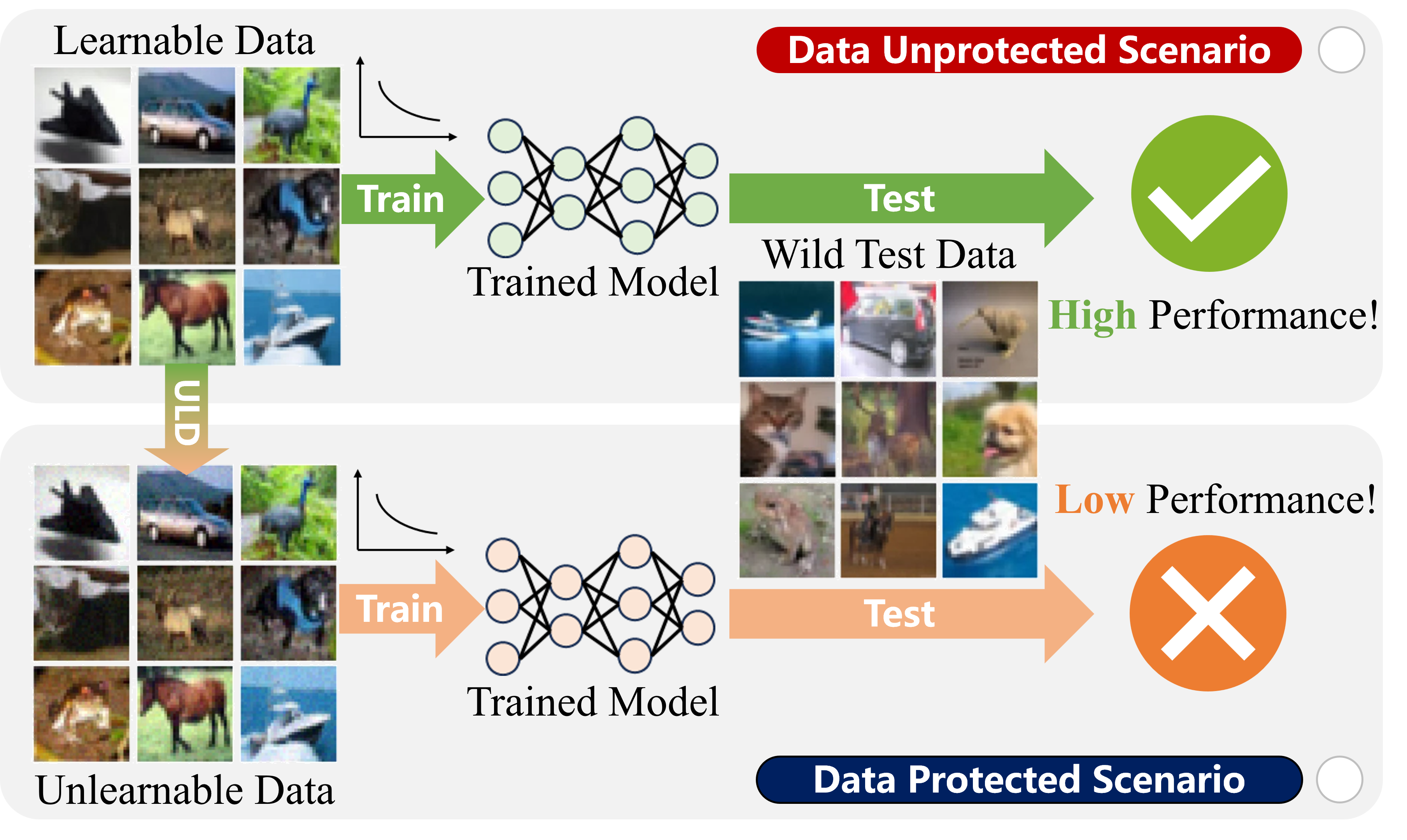
Unlearnable data (ULD) has emerged as an innovative defense technique to prevent machine learning models from learning meaningful patterns from specific data, thus protecting data privacy and security. By introducing perturbations to the training data, ULD degrades model performance, making it difficult for unauthorized models to extract useful representations. Despite the growing significance of ULD, existing surveys predominantly focus on related fields, such as adversarial attacks and machine unlearning, with little attention given to ULD as an independent area of study. This survey fills that gap by offering a comprehensive review of ULD, examining unlearnable data generation methods, public benchmarks, evaluation metrics, theoretical foundations and practical applications. We compare and contrast different ULD approaches, analyzing their strengths, limitations, and trade-offs related to unlearnability, imperceptibility, efficiency and robustness. Moreover, we discuss key challenges, such as balancing perturbation imperceptibility with model degradation and the computational complexity of ULD generation. Finally, we highlight promising future research directions to advance the effectiveness and applicability of ULD, underscoring its potential to become a crucial tool in the evolving landscape of data protection in machine learning.
翻译:暂无翻译