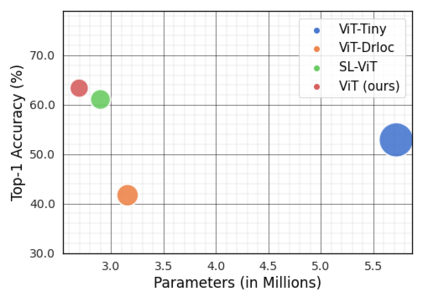
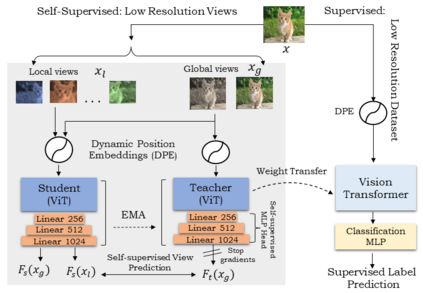
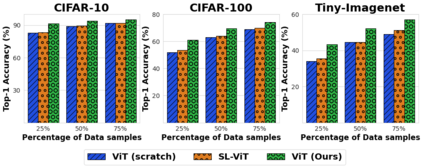
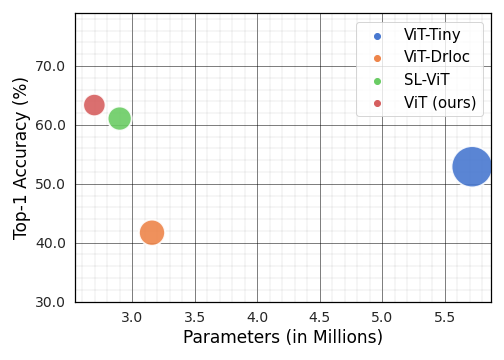
Vision Transformer (ViT), a radically different architecture than convolutional neural networks offers multiple advantages including design simplicity, robustness and state-of-the-art performance on many vision tasks. However, in contrast to convolutional neural networks, Vision Transformer lacks inherent inductive biases. Therefore, successful training of such models is mainly attributed to pre-training on large-scale datasets such as ImageNet with 1.2M or JFT with 300M images. This hinders the direct adaption of Vision Transformer for small-scale datasets. In this work, we show that self-supervised inductive biases can be learned directly from small-scale datasets and serve as an effective weight initialization scheme for fine-tuning. This allows to train these models without large-scale pre-training, changes to model architecture or loss functions. We present thorough experiments to successfully train monolithic and non-monolithic Vision Transformers on five small datasets including CIFAR10/100, CINIC10, SVHN, Tiny-ImageNet and two fine-grained datasets: Aircraft and Cars. Our approach consistently improves the performance of Vision Transformers while retaining their properties such as attention to salient regions and higher robustness. Our codes and pre-trained models are available at: https://github.com/hananshafi/vits-for-small-scale-datasets.
翻译:视觉变异器(ViT)是一个完全不同于连锁神经网络的架构,它提供了多种优势,包括设计简单、稳健和最先进的许多视觉任务业绩。然而,与视觉变异器相比,视觉变异器缺乏内在的感官偏向性。因此,成功培训这些模型的主要原因是对大型数据集,如图像网络(图象网络,使用1.2M或JFT,使用300M图像)等进行预先培训。这阻碍了视觉变异器对小型数据集的直接调整。在这项工作中,我们表明,自上而下的感知偏差可以直接从小规模数据集中学习,并用作用于微调的有效权重初始化计划。这样可以在没有大规模预培训、改变模型结构或损失功能的情况下对这些模型进行培训。我们展示了在五个小数据集(包括CIFAR10/100、CINIC10、SVHN、Timy-ImageNet和两个微缩缩缩缩缩的数据系统)上成功培训单项和非单项和非图变变形变形变形器的彻底实验。我们不断改进了这些变形/变形模型的特性和变形系统。我们在变形变形/变形变形变形模型中不断改进了我们的变形/变形变形模型。