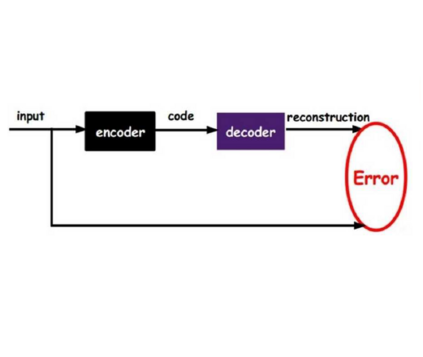
Masked autoencoders (MAEs) have established themselves as a powerful method for unsupervised pre-training for computer vision tasks. While vanilla MAEs put equal emphasis on reconstructing the individual parts of the image, we propose to inform the reconstruction process through an attention-guided loss function. By leveraging advances in unsupervised object discovery, we obtain an attention map of the scene which we employ in the loss function to put increased emphasis on reconstructing relevant objects, thus effectively incentivizing the model to learn more object-focused representations without compromising the established masking strategy. Our evaluations show that our pre-trained models learn better latent representations than the vanilla MAE, demonstrated by improved linear probing and k-NN classification results on several benchmarks while at the same time making ViTs more robust against varying backgrounds.
翻译:暂无翻译