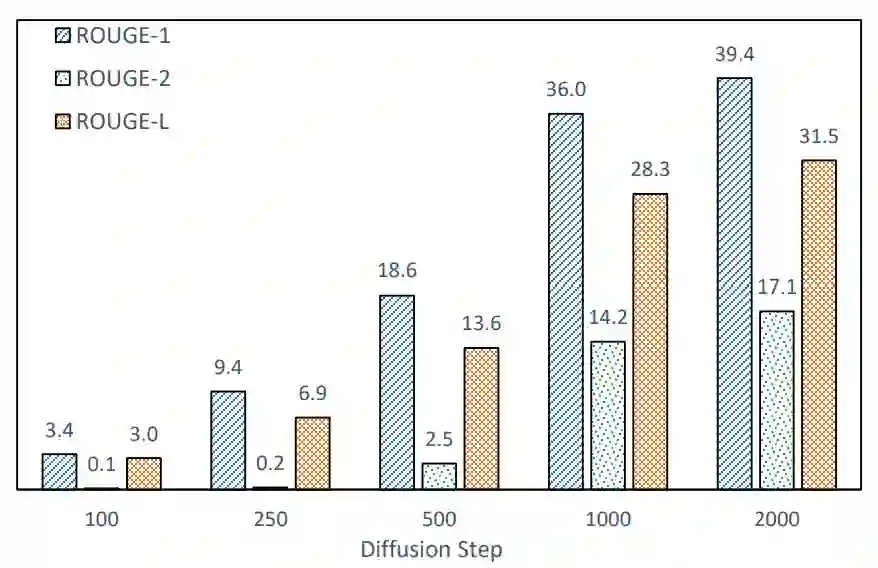
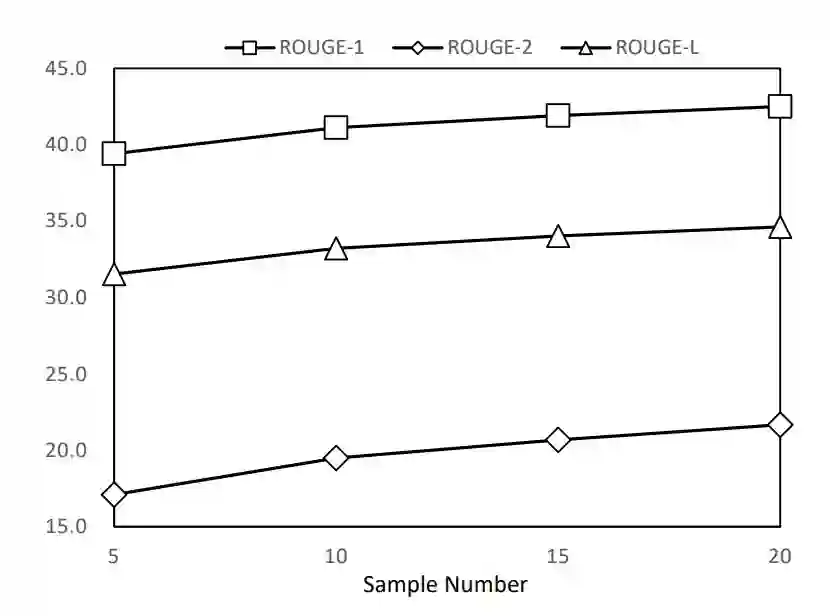
In this paper, we propose a large-scale language pre-training for text GENeration using dIffusion modEl, which is named GENIE. GENIE is a pre-training sequence-to-sequence text generation model which combines Transformer and diffusion. The diffusion model accepts the latent information from the encoder, which is used to guide the denoising of the current time step. After multiple such denoise iterations, the diffusion model can restore the Gaussian noise to the diverse output text which is controlled by the input text. Moreover, such architecture design also allows us to adopt large scale pre-training on the GENIE. We propose a novel pre-training method named continuous paragraph denoise based on the characteristics of the diffusion model. Extensive experiments on the XSum, CNN/DailyMail, and Gigaword benchmarks shows that GENIE can achieves comparable performance with various strong baselines, especially after pre-training, the generation quality of GENIE is greatly improved. We have also conduct a lot of experiments on the generation diversity and parameter impact of GENIE. The code for GENIE will be made publicly available.
翻译:在本文中,我们提议使用称为GENIE的“FIfuncul mod”(GENIE)对文本GENE进行大规模语言预培训。GENIE是一个将变异器与扩散结合起来的训练前序列到序列的文本生成模型。扩散模型接受编码器的潜在信息,用于指导当前时间步骤的去除。在多次这种隐蔽循环之后,扩散模型可以将高斯噪音恢复到由输入文本控制的多种输出文本中。此外,这种结构设计还使我们能够在GENIE上采用大型的预培训。我们根据扩散模型的特点提出了一个名为连续段落的新的培训前方法。关于XSum、CNN/DailyMail和Gigaword基准的广泛实验表明,GENIE能够以各种强的基线实现可比较的性能,特别是在培训前,GENIE的生成质量大为改善。我们还就GENIE的生成多样性和参数影响进行了许多实验。我们将公开提供GENIE的代码。