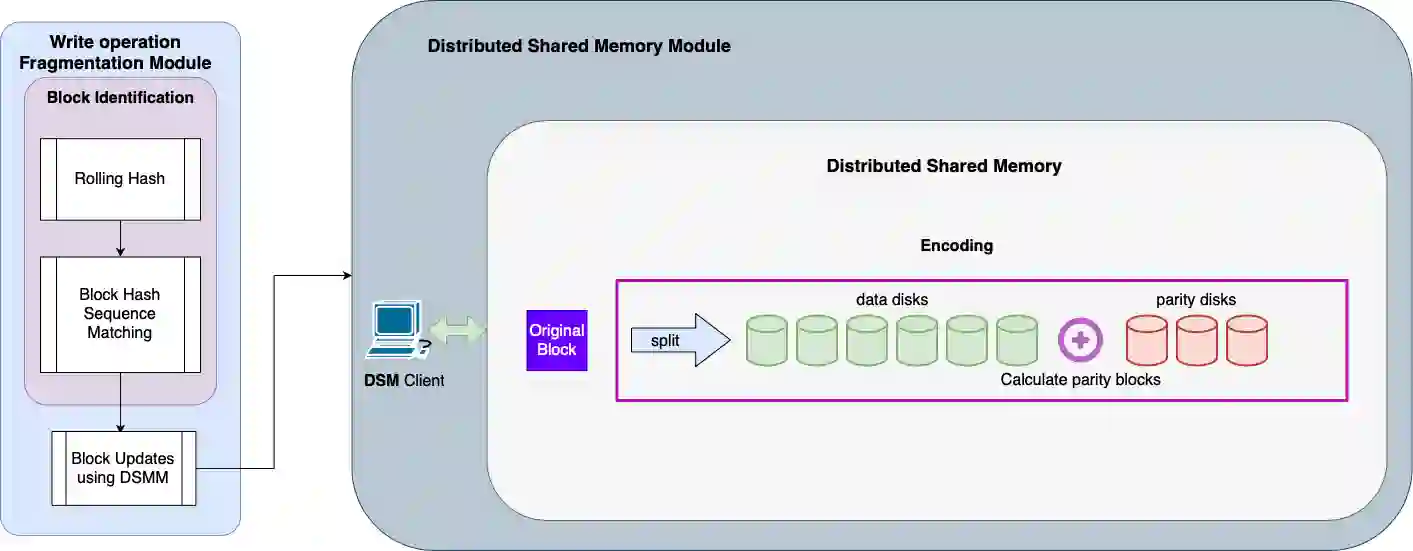
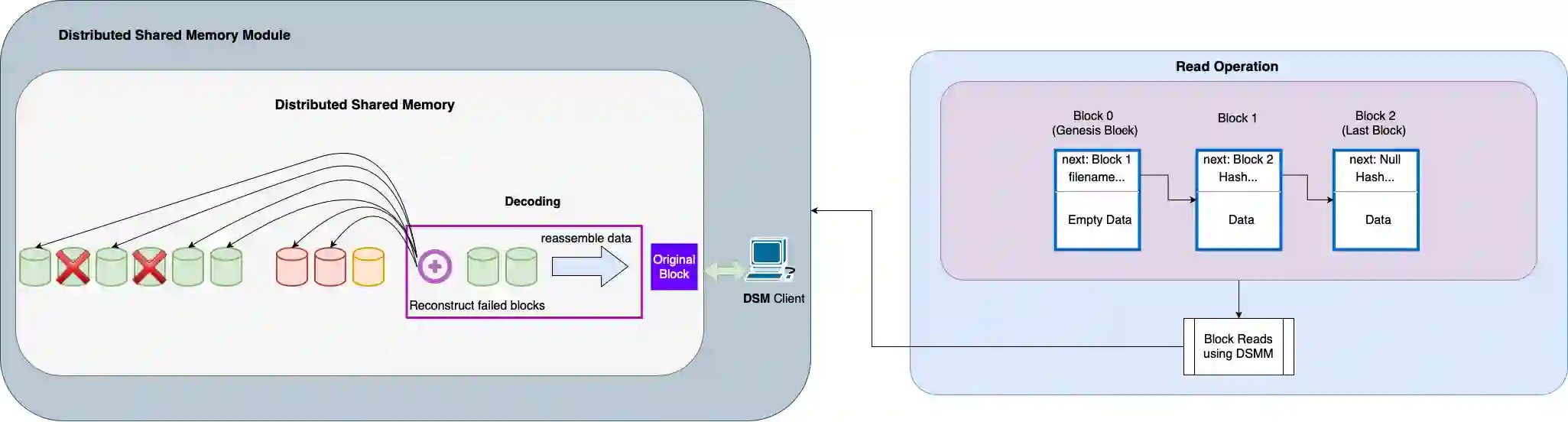
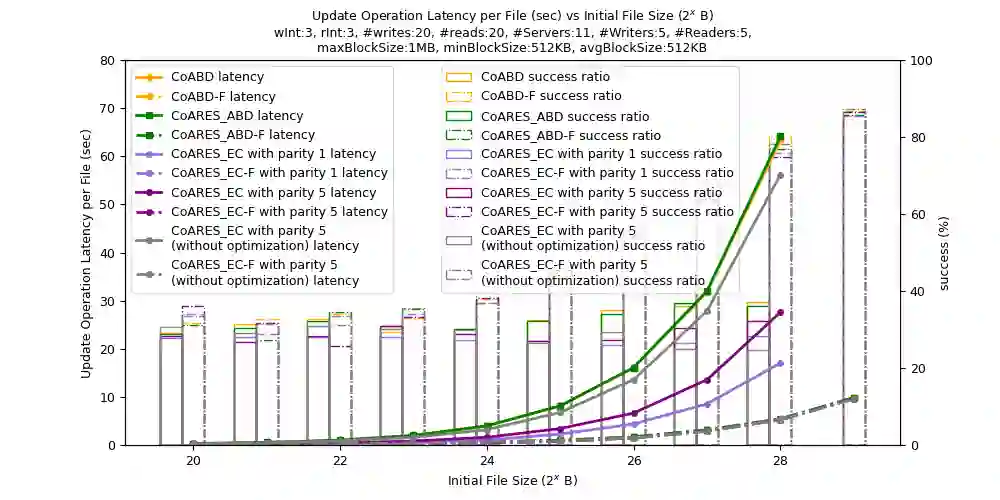
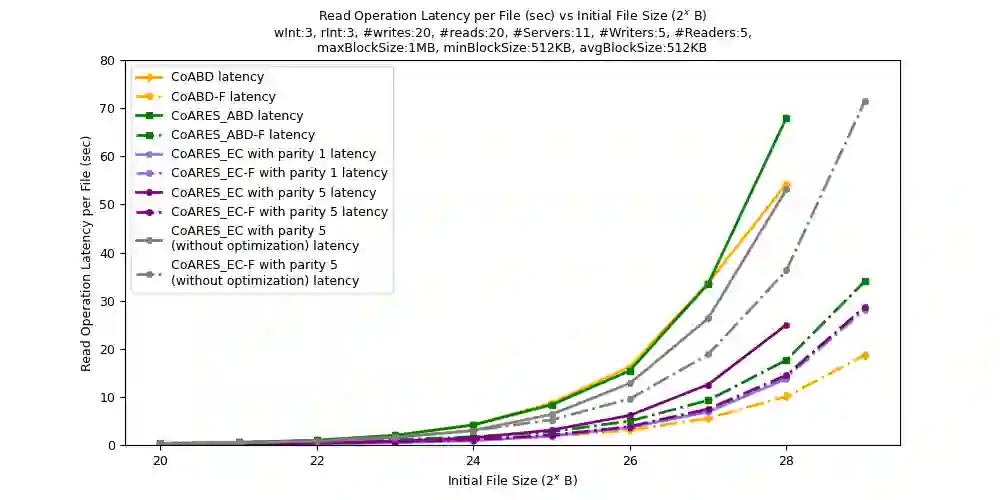
Data availability is one of the most important features in distributed storage systems, made possible by data replication. Nowadays data are generated rapidly and the goal to develop efficient, scalable and reliable storage systems has become one of the major challenges for high performance computing. In this work, we develop a dynamic, robust and strongly consistent distributed storage implementation suitable for handling large objects (such as files). We do so by integrating an Adaptive, Reconfigurable, Atomic Storage framework, called ARES, with a distributed file system, called COBFS, which relies on a block fragmentation technique to handle large objects. With the addition of ARES, we also enable the use of an erasure-coded algorithm to further split our data and to potentially improve storage efficiency at the replica servers and operation latency. To put the practicality of our outcomes at test, we conduct an in-depth experimental evaluation on the Emulab and AWS EC2 testbeds, illustrating the benefits of our approaches, as well as other interesting tradeoffs.
翻译:数据提供是分布式储存系统的最重要特征之一,通过数据复制而成为可能。现在,数据迅速生成,开发高效、可扩展和可靠的储存系统的目标已成为高性能计算的主要挑战之一。在这项工作中,我们开发了一种动态的、稳健的和强烈一致的分布式储存实施,适合于处理大型物体(如文件),我们这样做的方法是整合一个适应性、可重新配置的原子储存框架,称为ARES,并有一个分布式文件系统,称为COBFS,它依靠块分割技术处理大型物体。加上ARES,我们还能够使用一种取消式编码算法,进一步分割我们的数据,并有可能提高复制服务器和运行时间的存储效率。为了测试我们结果的实际性,我们对Emulab和AWS EC2试验台进行了深入的实验性评估,说明我们方法的好处以及其他有趣的交换。