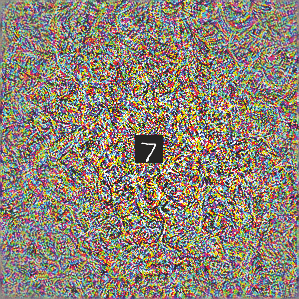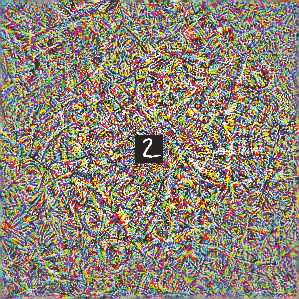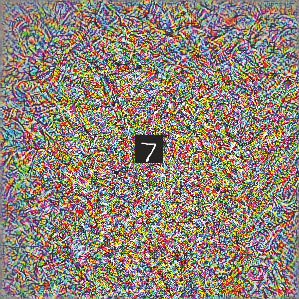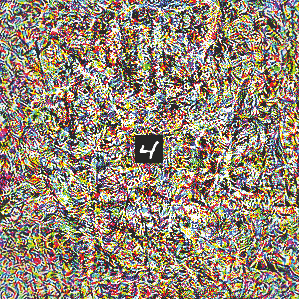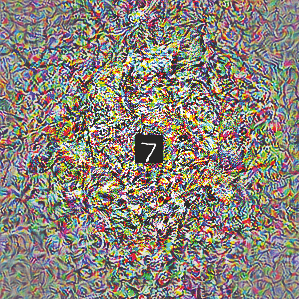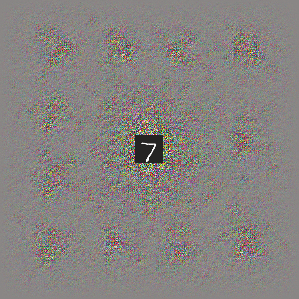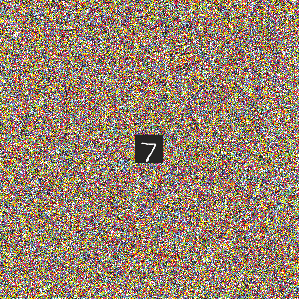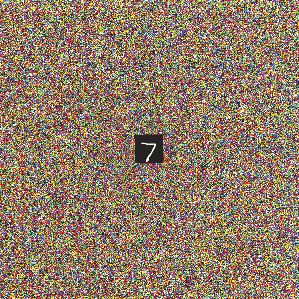Deep neural networks are susceptible to adversarial attacks. In computer vision, well-crafted perturbations to images can cause neural networks to make mistakes such as identifying a panda as a gibbon or confusing a cat with a computer. Previous adversarial examples have been designed to degrade performance of models or cause machine learning models to produce specific outputs chosen ahead of time by the attacker. We introduce adversarial attacks that instead reprogram the target model to perform a task chosen by the attacker---without the attacker needing to specify or compute the desired output for each test-time input. This attack is accomplished by optimizing for a single adversarial perturbation, of unrestricted magnitude, that can be added to all test-time inputs to a machine learning model in order to cause the model to perform a task chosen by the adversary when processing these inputs---even if the model was not trained to do this task. These perturbations can be thus considered a program for the new task. We demonstrate adversarial reprogramming on six ImageNet classification models, repurposing these models to perform a counting task, as well as two classification tasks: classification of MNIST and CIFAR-10 examples presented within the input to the ImageNet model.
翻译:深心神经网络很容易受到对抗性攻击。 在计算机视觉中, 精心设计的图像扰动可能导致神经网络错误, 如将熊猫确定为螺旋形或将猫与计算机混为一体。 先前的对抗性例子旨在降低模型的性能, 或导致机器学习模型产生特定产出, 以便提前由攻击者选择。 我们引入对抗性攻击, 而不是重新编程目标模型来执行攻击者选择的任务- 攻击者不需要为每个测试时间输入指定或计算预期产出。 此次攻击是通过优化单一的对抗性扰动( 范围不限制) 来完成的。 可以在机器学习模型的所有试验时输入中添加, 以便让模型在处理这些输入时执行对手选择的任务。 即使模型没有经过训练来完成这项任务, 这些扰动可以因此被视为新任务的程序。 我们演示了6个图像网络分类模型的对抗性重新配置, 重新配置这些模型来完成一个计算任务, 并且将这些模型添加到机器学习模型的计算任务中, 作为两个分类: CIAR 和 IM IM 的模型 。