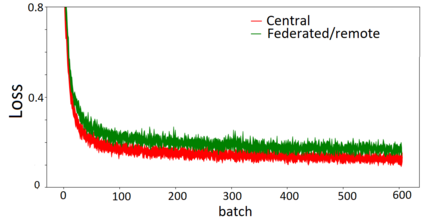
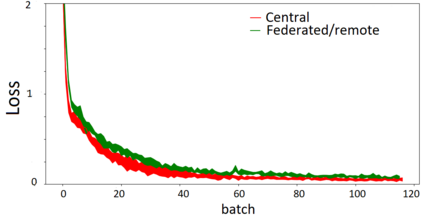
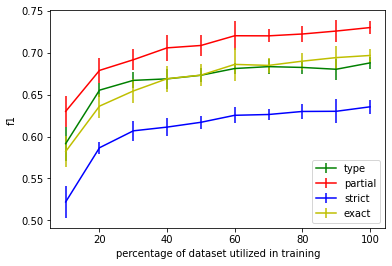
We curated WikiPII, an automatically labeled dataset composed of Wikipedia biography pages, annotated for personal information extraction. Although automatic annotation can lead to a high degree of label noise, it is an inexpensive process and can generate large volumes of annotated documents. We trained a BERT-based NER model with WikiPII and showed that with an adequately large training dataset, the model can significantly decrease the cost of manual information extraction, despite the high level of label noise. In a similar approach, organizations can leverage text mining techniques to create customized annotated datasets from their historical data without sharing the raw data for human annotation. Also, we explore collaborative training of NER models through federated learning when the annotation is noisy. Our results suggest that depending on the level of trust to the ML operator and the volume of the available data, distributed training can be an effective way of training a personal information identifier in a privacy-preserved manner. Research material is available at https://github.com/ratmcu/wikipiifed.
翻译:我们开发了由维基百科传记页组成的自动标签数据集WikiPII,这是一个由维基百科传记页组成的自动标签数据集,供个人信息提取之用。虽然自动注解可导致高程度的标签噪音,但这是一个廉价的过程,可以产生大量附加说明的文件。我们与维基百科一起培训了一个基于BERT的NER模型,并表明,有了足够大的培训数据集,该模型可以大大减少人工信息提取的成本,尽管标签噪音很大。在类似办法中,各组织可以利用文本挖掘技术,从历史数据中创建定制的附加说明的数据集,而不必为人类注解分享原始数据。此外,我们还探索通过在注解噪音时的联结学习对NER模型进行协作培训。我们的结果表明,根据对ML操作员的信任程度和现有数据的数量,分发的培训可以成为以保密方式培训个人信息标识的有效方式。研究材料可在https://github.com/ratmcu/wikipifed上查阅。