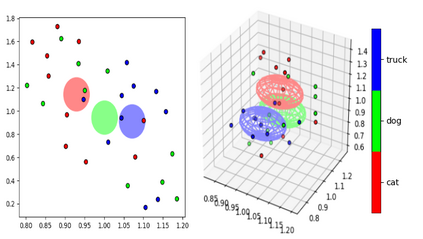
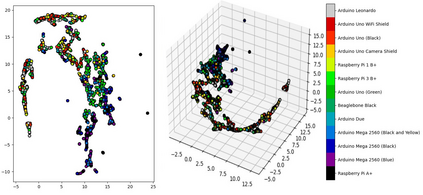
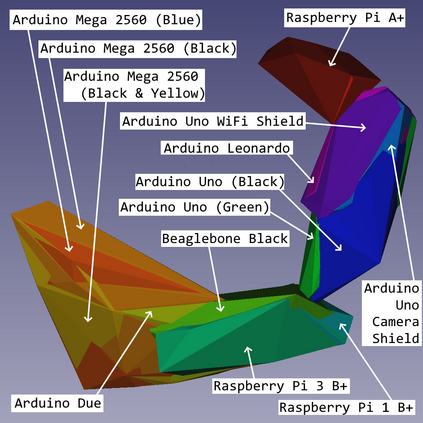
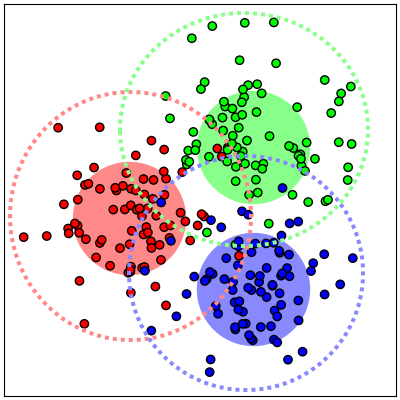
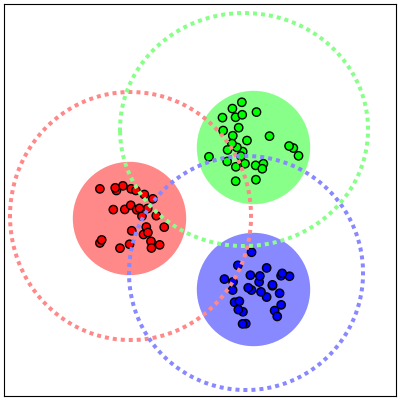
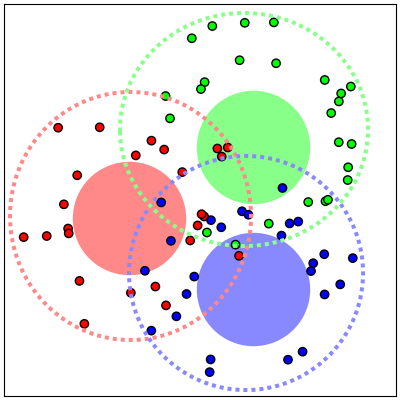
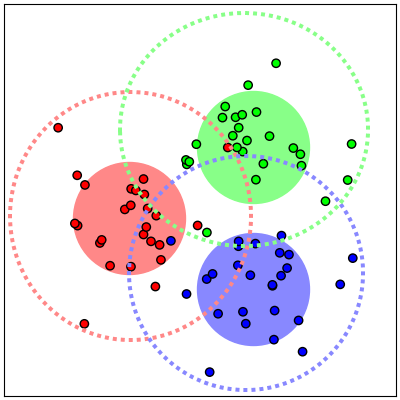
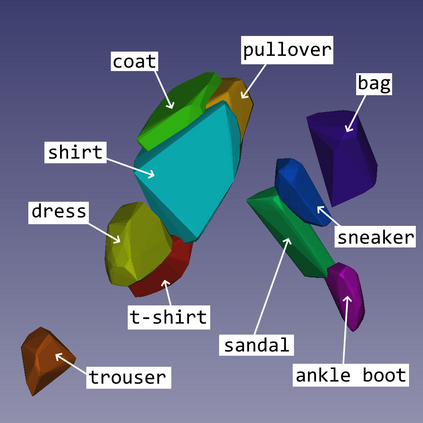
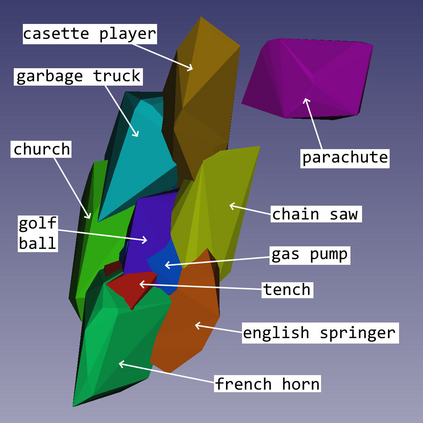
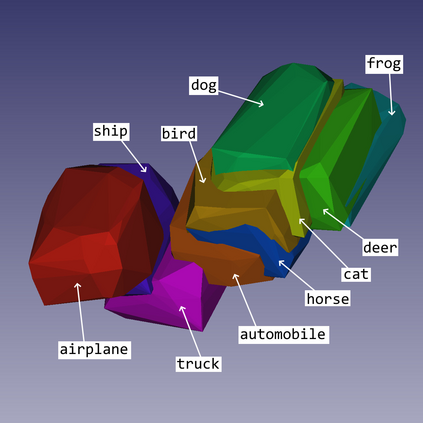
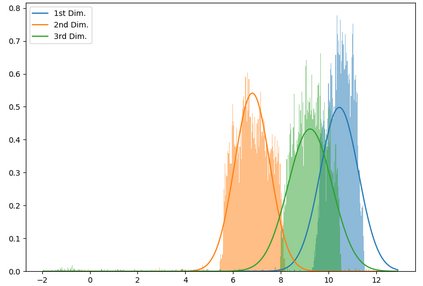
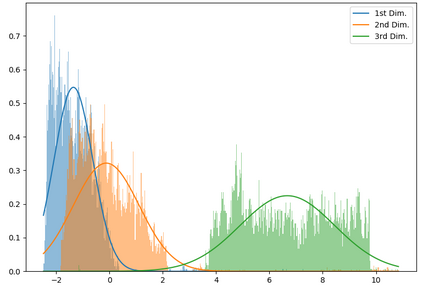
We show that, for each of five datasets of increasing complexity, certain training samples are more informative of class membership than others. These samples can be identified a priori to training by analyzing their position in reduced dimensional space relative to the classes' centroids. Specifically, we demonstrate that samples nearer the classes' centroids are less informative than those that are furthest from it. For all five datasets, we show that there is no statistically significant difference between training on the entire training set and when excluding up to 2% of the data nearest to each class's centroid.
翻译:我们显示,对于日益复杂的五个数据集中的每一数据集,某些培训样本比其他数据集更能提供课堂成员的信息。这些样本可以通过分析其相对于各类的中央机器人在较低维度空间的位置来先验地识别为培训对象。具体地说,我们证明,接近各类的中央机器人的样本比离该类最远的样本更缺乏信息。对于所有五个数据集,我们显示,整个培训数据集的培训与排除每个类的中央机器人近2%的数据时,在统计学上没有显著的差别。