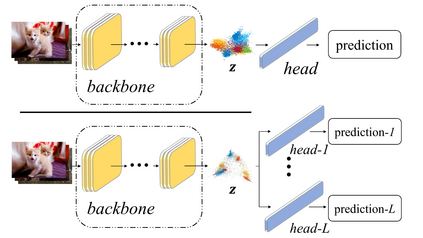
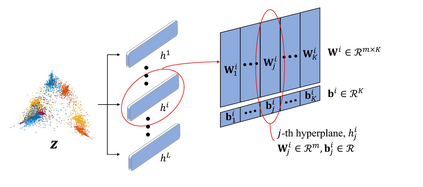
Deep Neural Networks (DNNs) are vulnerable to invisible perturbations on the images generated by adversarial attacks, which raises researches on the adversarial robustness of DNNs. A series of methods represented by the adversarial training and its variants have proven as one of the most effective techniques in enhancing the DNN robustness. Generally, adversarial training focuses on enriching the training data by involving perturbed data. Despite of the efficiency in defending specific attacks, adversarial training is benefited from the data augmentation, which does not contribute to the robustness of DNN itself and usually suffers from accuracy drop on clean data as well as inefficiency in unknown attacks. Towards the robustness of DNN itself, we propose a novel defense that aims at augmenting the model in order to learn features adaptive to diverse inputs, including adversarial examples. Specifically, we introduce multiple paths to augment the network, and impose orthogonality constraints on these paths. In addition, a margin-maximization loss is designed to further boost DIversity via Orthogonality (DIO). Extensive empirical results on various data sets, architectures, and attacks demonstrate the adversarial robustness of the proposed DIO.
翻译:对抗性训练及其变式所呈现的一系列方法被证明是增强DNN稳健性的最有效方法之一。一般而言,对抗性训练侧重于通过使用扰动数据来丰富培训数据。尽管在防御特定攻击方面的效率很高,但对抗性训练得益于数据增强,这无助于DNN本身的稳健性,通常还受到清洁数据准确性下降以及不明攻击效率低下的影响。为了提高DNN本身的稳健性,我们提出了新的辩护,目的是加强模型,以学习适应多种投入的特点,包括对抗性例子。具体地说,我们引入多种途径来扩大网络,并在这些路径上施加或分层限制。此外,差-峰化损失的目的是通过Orthorticity进一步增强DNN的多样化。关于各种数据集、架构和攻击的深入经验结果展示了拟议的DIO的稳健性。