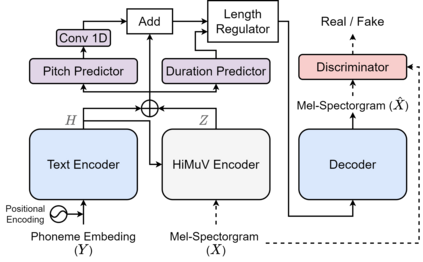
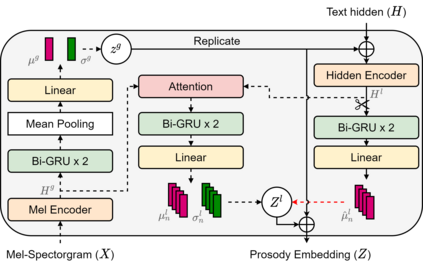
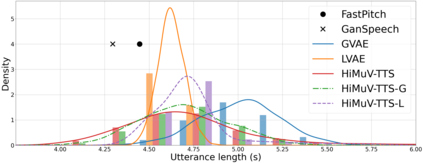
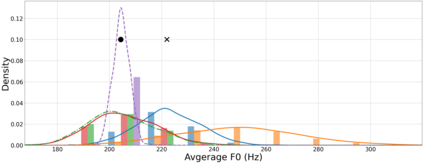
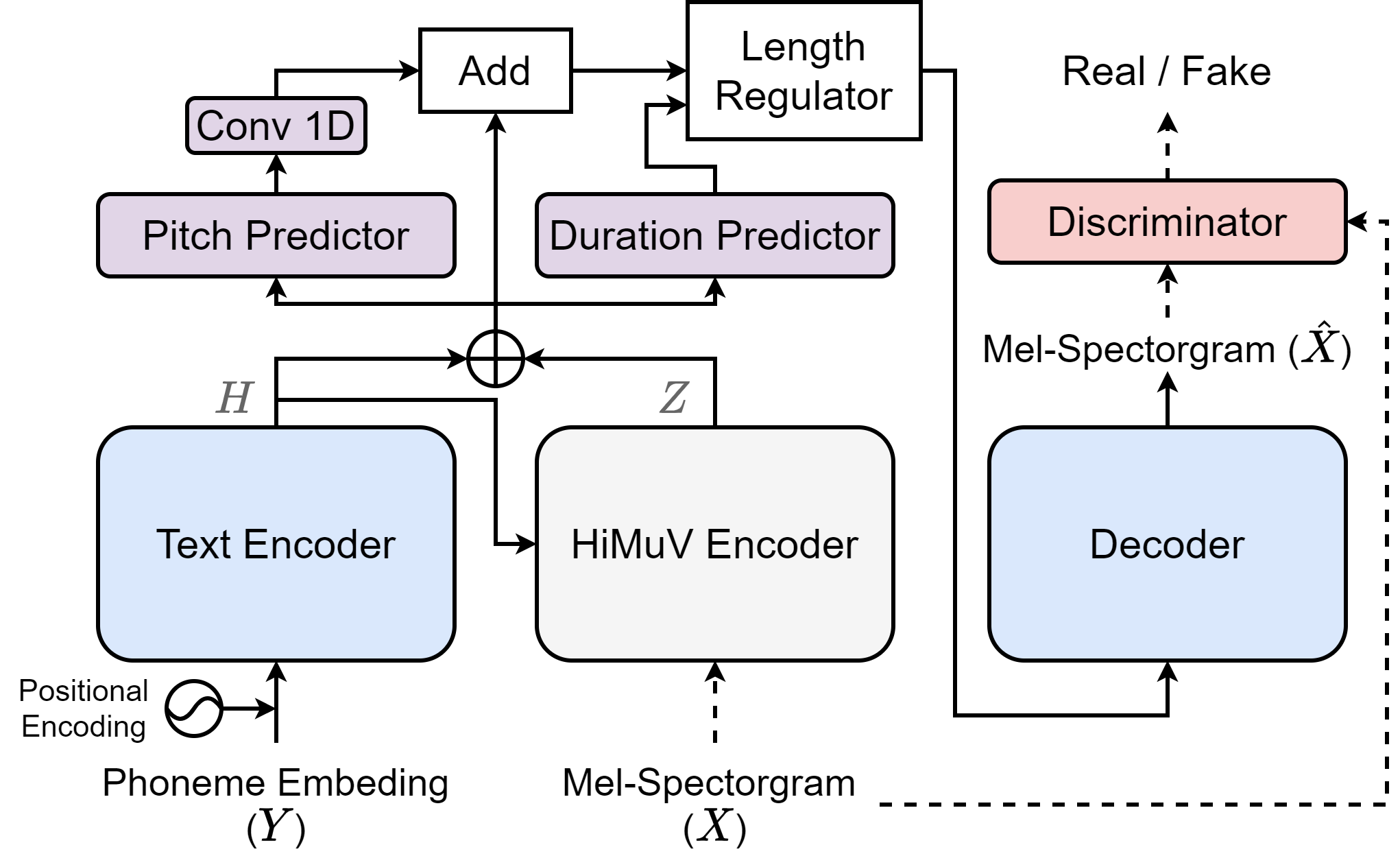
This paper proposes a hierarchical and multi-scale variational autoencoder-based non-autoregressive text-to-speech model (HiMuV-TTS) to generate natural speech with diverse speaking styles. Recent advances in non-autoregressive TTS (NAR-TTS) models have significantly improved the inference speed and robustness of synthesized speech. However, the diversity of speaking styles and naturalness are needed to be improved. To solve this problem, we propose the HiMuV-TTS model that first determines the global-scale prosody and then determines the local-scale prosody via conditioning on the global-scale prosody and the learned text representation. In addition, we improve the quality of speech by adopting the adversarial training technique. Experimental results verify that the proposed HiMuV-TTS model can generate more diverse and natural speech as compared to TTS models with single-scale variational autoencoders, and can represent different prosody information in each scale.
翻译:本文提出一个基于等级和多尺度的自动变换码、基于非自动变式文本到语音的模型(HiMUV-TTS),以产生具有不同语言风格的自然演讲。非自动变换式TTS(NAR-TTS)模型最近的进展大大提高了合成语音的推论速度和稳健性。然而,需要改进语音样式和自然性的多样性。为了解决这一问题,我们提议HIMUV-TTS模型,首先确定全球规模的代理操作,然后通过全球规模的代理操作和学习的文本代表来决定本地规模的代理操作。此外,我们通过采用对抗性培训技术来提高演讲质量。实验结果证实,拟议的HMUV-TTS模型与具有单一规模自动变换器的TTS模型相比,能够产生更多多样性和自然的演讲,并可以代表每个规模的不同代理信息。