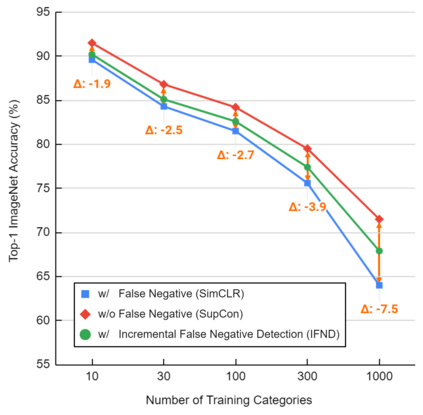
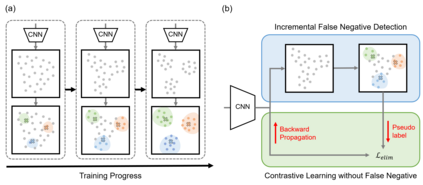
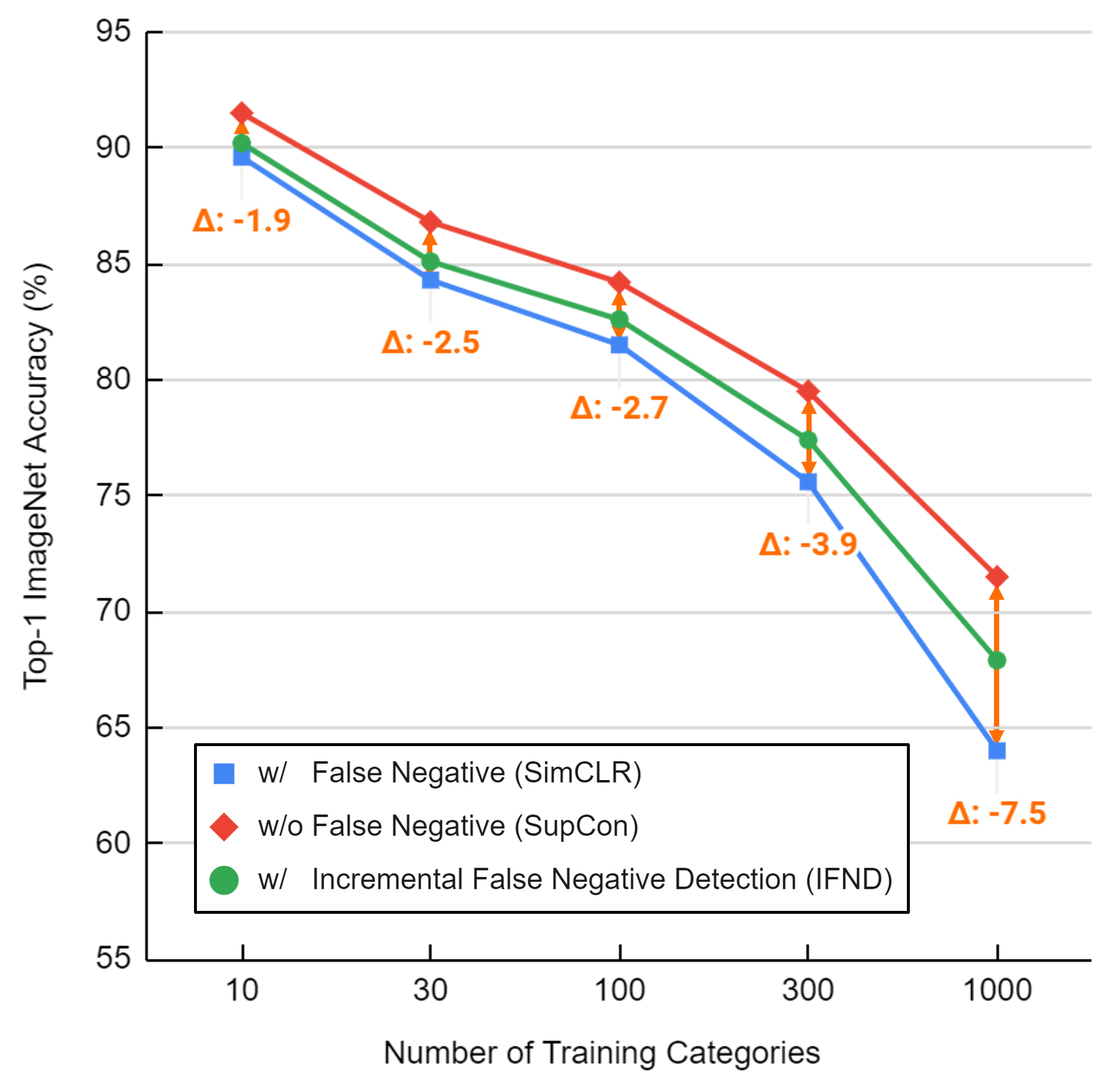
Self-supervised learning has recently shown great potential in vision tasks via contrastive learning, which aims to discriminate each image, or instance, in the dataset. However, such instance-level learning ignores the semantic relationship between instances and repels the anchor equally from the semantically similar samples, termed as false negatives. In this work, we first empirically highlight that the unfavorable effect from false negatives is more significant for the datasets containing images with more semantic concepts. To address the issue, we introduce a novel incremental false negative detection for self-supervised contrastive learning. Following the training process, when the encoder is gradually better-trained and the embedding space becomes more semantically structural, our method incrementally detects more reliable false negatives. Subsequently, during contrastive learning, we discuss two strategies to explicitly remove the detected false negatives. Extensive experiments show that our proposed method outperforms other self-supervised contrastive learning frameworks on multiple benchmarks within a limited compute.
翻译:自我监督的学习最近通过对比学习展示了视觉任务的巨大潜力。 对比学习的目的是在数据集中区分每个图像或实例。 但是, 这样的实例级学习忽略了实例之间的语义关系, 并且从语义上相似的样本中平等地反射锚, 被称为假底片。 在这项工作中, 我们首先从经验上强调, 假底片的不利效应对于含有更多语义概念的图像的数据集来说更为重要。 为了解决这个问题, 我们引入了一种新颖的增量假否定检测方法, 用于自我监督对比学习。 在培训过程中, 当编码器逐渐得到更好的训练, 嵌入空间变得更具语义性结构时, 我们的方法逐渐地检测出更可靠的假底片。 在对比学习过程中, 我们先讨论两种战略, 以明确清除检测到的假底片。 广泛的实验显示, 我们所提议的方法比其他在有限的解算范围内的多基准上自我监督的对比式学习框架要强得多。