开源在线机器学习Online Learning/Incremental Learning库-creme介绍
最近在学习实时机器学习或者说增量学习相关的内容,目前中文资料相关的介绍非常少,今天借着creme这个库介绍下Online Learning的原理,以及Online Learning和Batch Learning的一些区别。
Batch就是目前常用的计算模式,需要离线数据,离线训练,离线评估,然后上线。
离线的好处就是比较稳定,可以用大的数据量去训练和评估,如果模型效果不好也方便替换。
OnlineLearning更多地是一个实时运行的体系,实时有样本产生,实时提取特征并且和目标列拼接成样本,实时评估和训练。
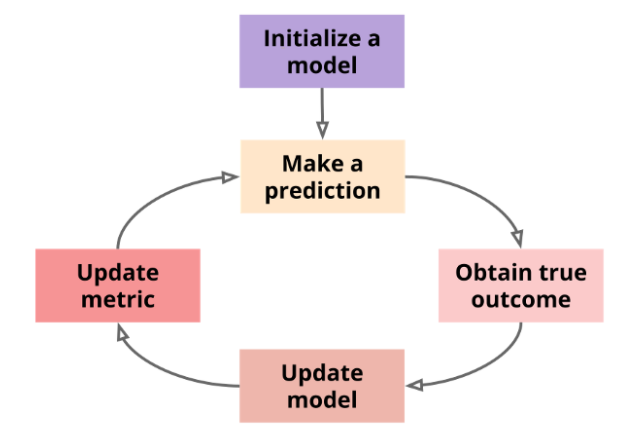
Online Learning需要具备下述的几个特点:
数据从流式数据源获取,比如Kafka、MQ
可以对Mini Batch甚至单样本训练并产生新模型
特征和目标可以实时生成并实时拼接成样本
Online Learning优点很明显,就是可以对训练样本做实时的反馈。所以应用的场景也主要是互联网领域,对实时性要求很高的场景。在推荐广告领域,Online Learning后续非常有发挥的空间。

Online Learning的优势就是实时产出模型,数据的时效性强。之所以没有大范围普及,主要因为劣势也很明显,运维成本会比较高。比如如何保证实时样本拼接的准确性、如何确保实时评估的准确、线上模型出现问题如何回滚等。所以,Online Learning还没有非常好的开源解决方案,今天介绍的creme只能解决部分问题。
项目地址:https://github.com/creme-ml/creme
可以通过pip安装:pip install creme
这是一个专注做Online Learning的库,目前还没有集成tf、pytorch的能力,所以现在creme是自己实现一些单机可运行的增量学习的算法,可以实现one sample粒度的训练。
一些数据量不大,或者是想了解Online Learning机制的同学比较推荐,如果是企业生产的话,还是要等基于TensorFlow或者其它成熟框架的mini batch这样训练的能力。
creme的代码可读性很强,
from creme import linear_modelfrom creme import streamX_y = stream.iter_csv('some/csv/file.csv')model = linear_model.LogisticRegression()for x, y in X_y:model.fit_one(x, y)
有一个stream库可以实现流式的IO,这里接Kafka也是可以的。单样本训练直接可以用fit_one,这个命名满直接的。
from creme import linear_modelfrom cremeimport metricsfrom cremeimport streamX_y = stream.iter_csv('some/csv/file.csv')model = linear_model.LogisticRegression()metric = metrics.Accuracy()for x, y in X_y:y_pred = model.predict_one(x)model.fit_one(x, y)metric.update(y, y_pred)print(metric)
在评估的时候可以直接用metric.update函数去计算准确率,评估指标是通过真实的y值和预测出来的y_pred做对比。
下图展示的是creme已经支持的函数和算法:

总而言之,creme目前还是一个探索性的项目,在实际生产方面可能会有性能问题,不过是一个很好地了解Online Learning的材料。


