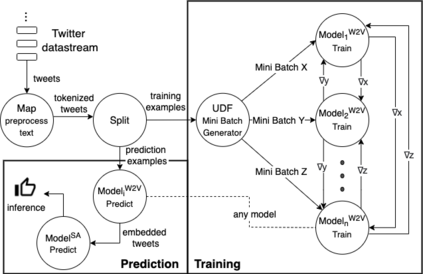
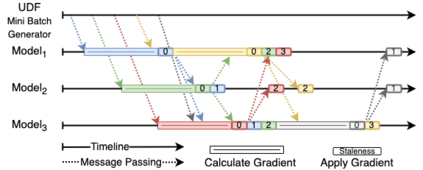
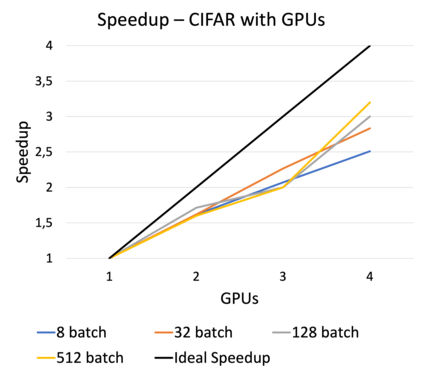
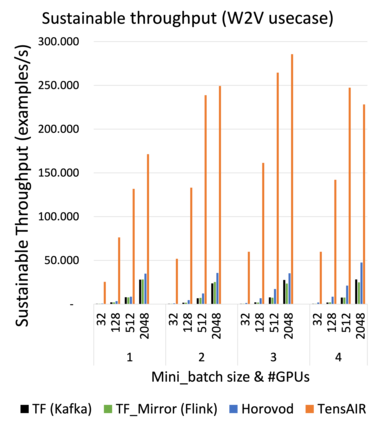
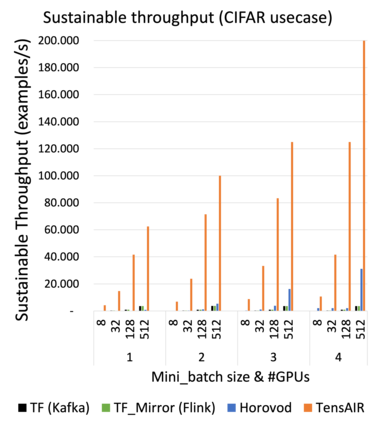
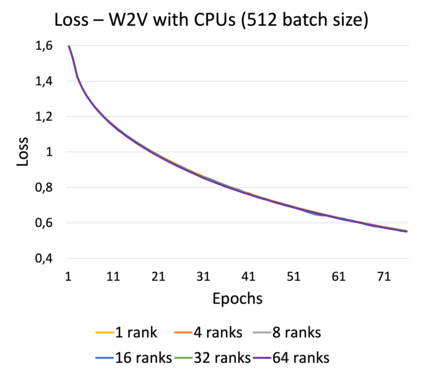
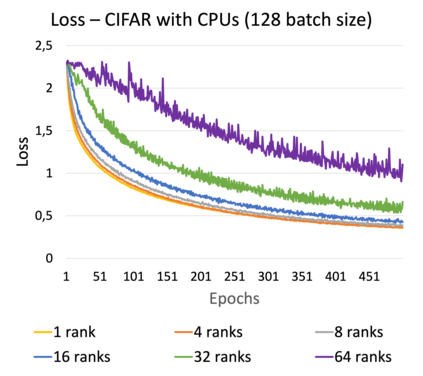
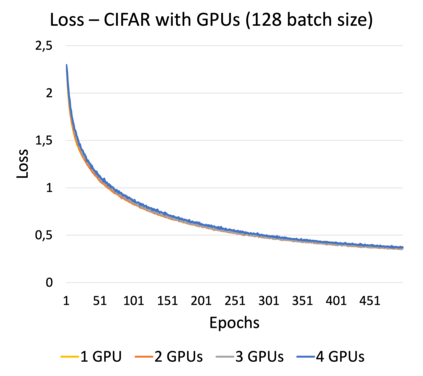
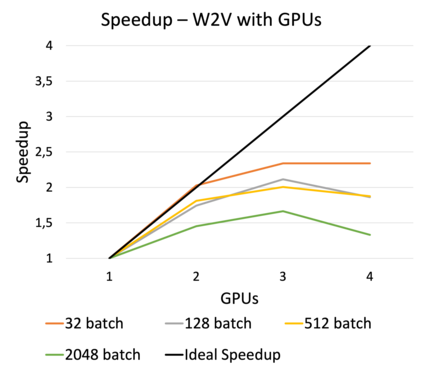
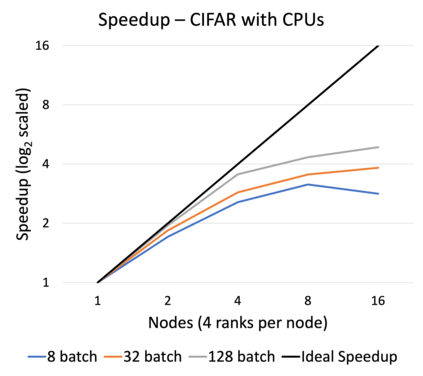
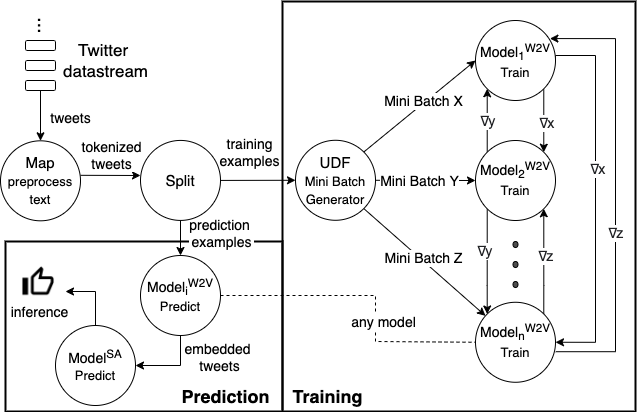
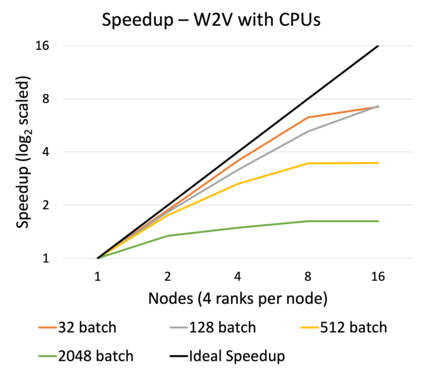Online learning (OL) from data streams is an emerging area of research that encompasses numerous challenges from stream processing, machine learning, and networking. Recent extensions of stream-processing platforms, such as Apache Kafka and Flink, already provide basic extensions for the training of neural networks in a stream-processing pipeline. However, these extensions are not scalable and flexible enough for many real-world use-cases, since they do not integrate the neural-network libraries as a first-class citizen into their architectures. In this paper, we present TensAIR, which provides an end-to-end dataflow engine for OL from data streams via a protocol to which we refer as asynchronous iterative routing. TensAIR supports the common dataflow operators, such as Map, Reduce, Join, and has been augmented by the data-parallel OL functions train and predict. These belong to the new Model operator, in which an initial TensorFlow model (either freshly initialized or pre-trained) is replicated among multiple decentralized worker nodes. Our decentralized architecture allows TensAIR to efficiently shard incoming data batches across the distributed model replicas, which in turn trigger the model updates via asynchronous stochastic gradient descent. We empirically demonstrate that TensAIR achieves a nearly linear scale-out in terms of (1) the number of worker nodes deployed in the network, and (2) the throughput at which the data batches arrive at the dataflow operators. We exemplify the versatility of TensAIR by investigating both sparse (Word2Vec) and dense (CIFAR-10) use-cases, for which we are able to demonstrate very significant performance improvements in comparison to Kafka, Flink, and Horovod. We also demonstrate the magnitude of these improvements by depicting the possibility of real-time concept drift adaptation of a sentiment analysis model trained over a Twitter stream.
翻译:来自数据流的在线学习(OL)是一个新兴的研究领域,它包含来自流处理、机器学习和网络建设的众多挑战。最近,流处理平台的扩展,如阿帕奇卡夫卡和弗林克,已经为在流处理管道中培训神经网络提供基本的扩展。然而,这些扩展对于许多真实世界使用案例来说,并不够可伸缩和灵活,因为它们没有将神经网络图书馆作为一流公民纳入它们的架构。本文介绍TensAIR,它通过协议为来自数据流的流提供端到端的数据流流引擎,我们称之为无同步迭代迭接路。TensAIR支持通用的数据流操作,例如地图、减少、合并,并且通过数据流流来扩大。这些扩展属于新的模型操作员,其中初始的TensorFlow模型(我们不是刚初始化的,也不是事先训练过的)也在多个分散的工人节点中复制。我们分散的架构允许TensAIR,将数据流到快速递增数据流,我们通过机变的模型显示一个快速递增数据。