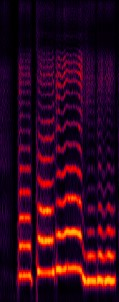
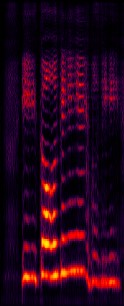
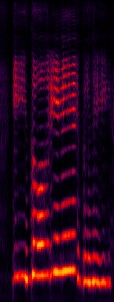
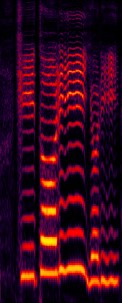
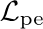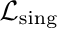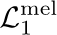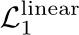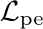The neural network (NN) based singing voice synthesis (SVS) systems require sufficient data to train well and are prone to over-fitting due to data scarcity. However, we often encounter data limitation problem in building SVS systems because of high data acquisition and annotation costs. In this work, we propose a Perceptual Entropy (PE) loss derived from a psycho-acoustic hearing model to regularize the network. With a one-hour open-source singing voice database, we explore the impact of the PE loss on various mainstream sequence-to-sequence models, including the RNN-based, transformer-based, and conformer-based models. Our experiments show that the PE loss can mitigate the over-fitting problem and significantly improve the synthesized singing quality reflected in objective and subjective evaluations.
翻译:以歌声合成(SVS)系统为基础的神经网络(NN)系统需要足够的数据来进行良好的培训,并且由于数据稀缺而容易过度适应。然而,由于数据获取和批注成本高,我们在建立SVS系统时常常遇到数据限制问题。在这项工作中,我们提议从心理声听模式中产生感知性催化(PE)损失,以规范网络。我们有一个一小时的开放源码歌声数据库,我们探索PE损失对各种主流序列到序列模型的影响,包括基于RNN、变压器和相容器的模型。我们的实验表明,PE损失可以缓解过度装配的问题,大大改善客观和主观评价中反映的合成歌声质量。