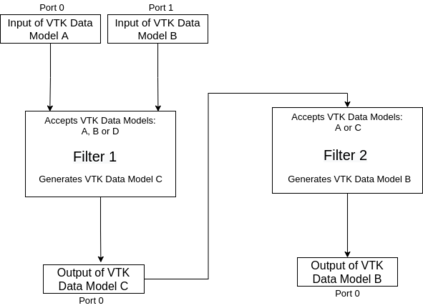
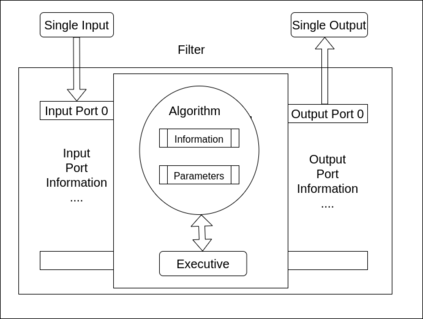
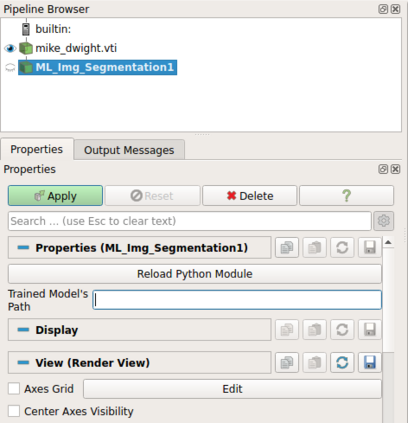
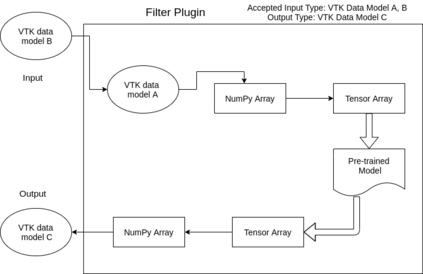
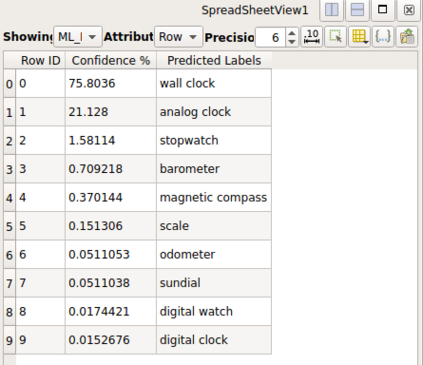
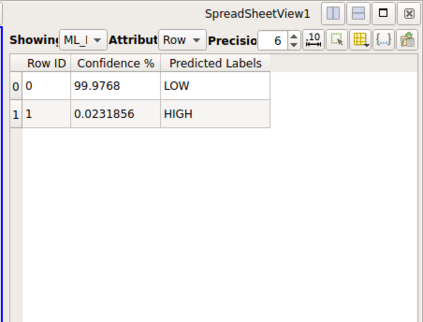
Recent progress in scientific visualization has expanded the scope of visualization from being merely a way of presentation to an analysis and discovery tool. A given visualization result is usually generated by applying a series of transformations or filters to the underlying data. Nowadays, such filters use deterministic algorithms to process the data. In this work, we aim at extending this methodology towards data-driven filters, thus filters that expose the abilities of pre-trained machine learning models to the visualization system. The use of such data-driven filters is of particular interest in fields like segmentation, classification, etc., where machine learning models regularly outperform existing algorithmic approaches. To showcase this idea, we couple Paraview, the well-known flow visualization tool, with PyTorch, a deep learning framework. Paraview is extended by plugins that allow users to load pre-trained models of their choice in the form of newly developed filters. The filters transform the input data by feeding it into the model and then provide the model's output as input to the remaining visualization pipeline. A series of simplistic use cases for segmentation and classification on image and fluid data is presented to showcase the technical applicability of such data-driven transformations in Paraview for future complex analysis tasks.
翻译:科学可视化的近期进展扩大了可视化的范围,从仅仅是一种演示方式,到分析和发现工具。给定的可视化结果通常是通过对基本数据应用一系列变换或过滤方法产生的。如今,这些过滤器使用确定性算法处理数据。在这项工作中,我们的目标是将这种方法扩大到数据驱动过滤器,从而将预培训机器学习模型的能力暴露到可视化系统的过滤器。使用这类数据驱动过滤器对诸如分解、分类等领域特别感兴趣,在这些领域,机器学习模型经常比现有算法方法更完善。为了展示这一想法,我们将Paraview、众所周知的流动可视化工具、PyTorrch、一个深层学习框架结合起来。Paraview通过插件扩展了这一方法,使用户能够以新开发的过滤器的形式装载其选择的预培训模型。过滤器将输入数据输入到模型中,然后将模型的输出结果作为剩余可视化管道的投入。在图像和液体的复杂分析中,将一系列用于分解和分类的简单使用案例展示。