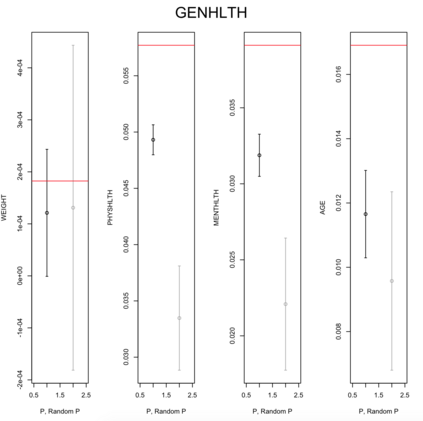
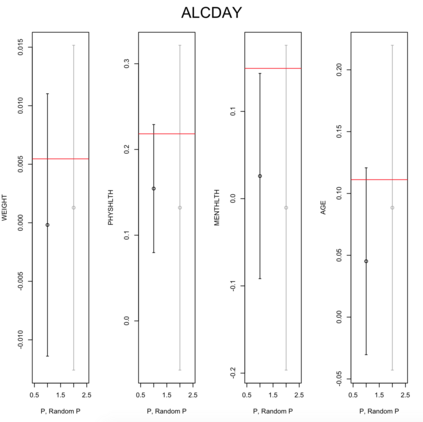
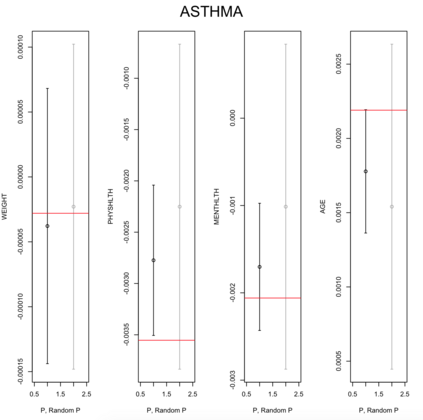
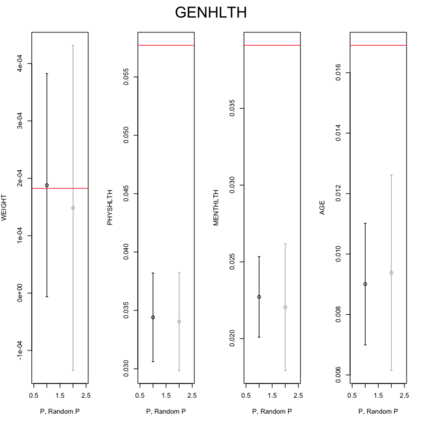
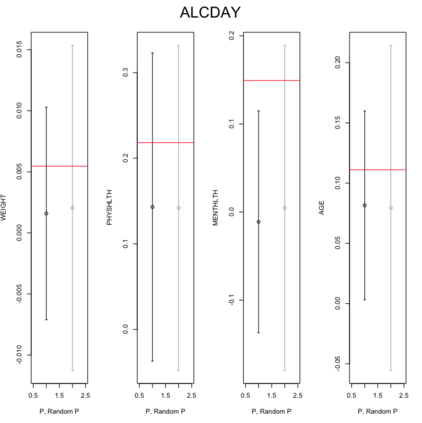
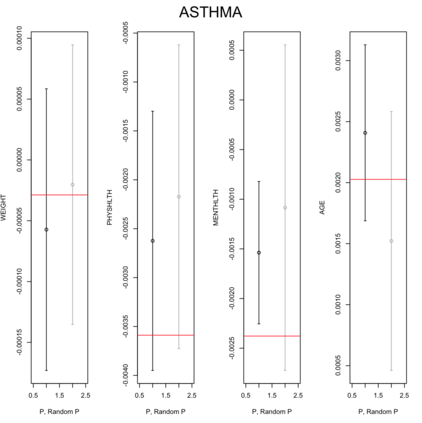
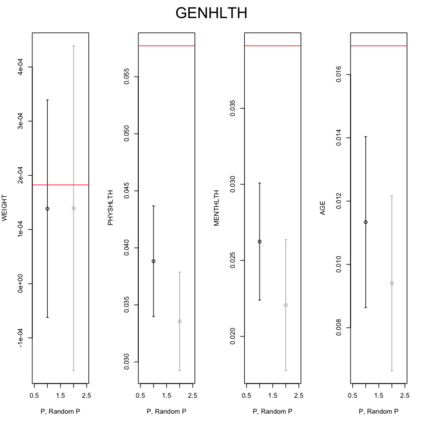
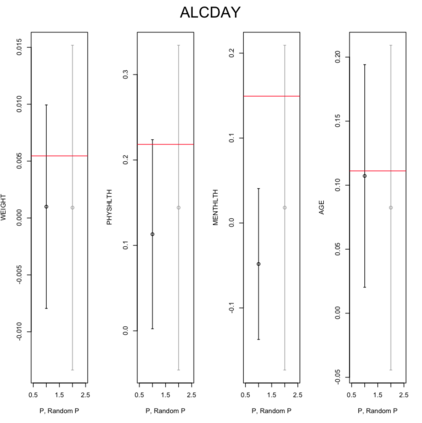
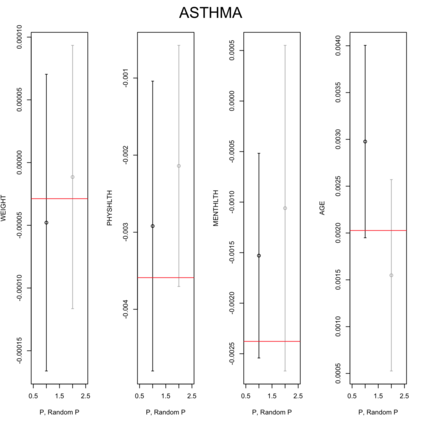
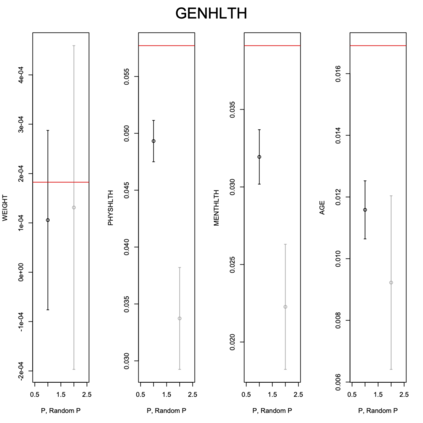
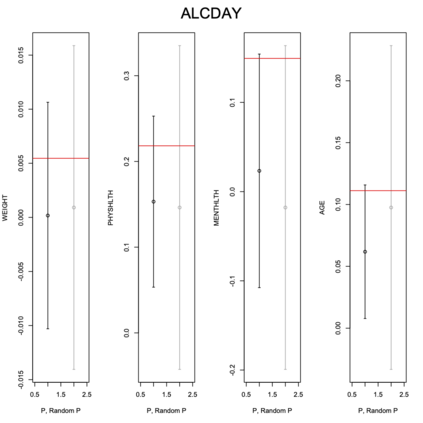
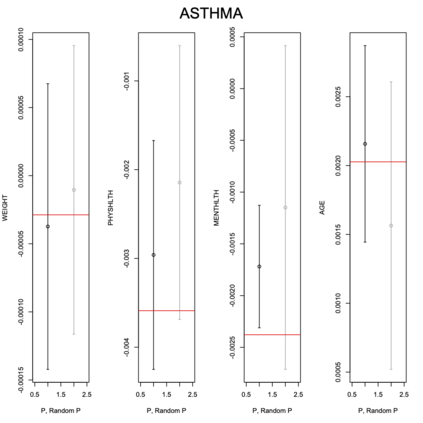
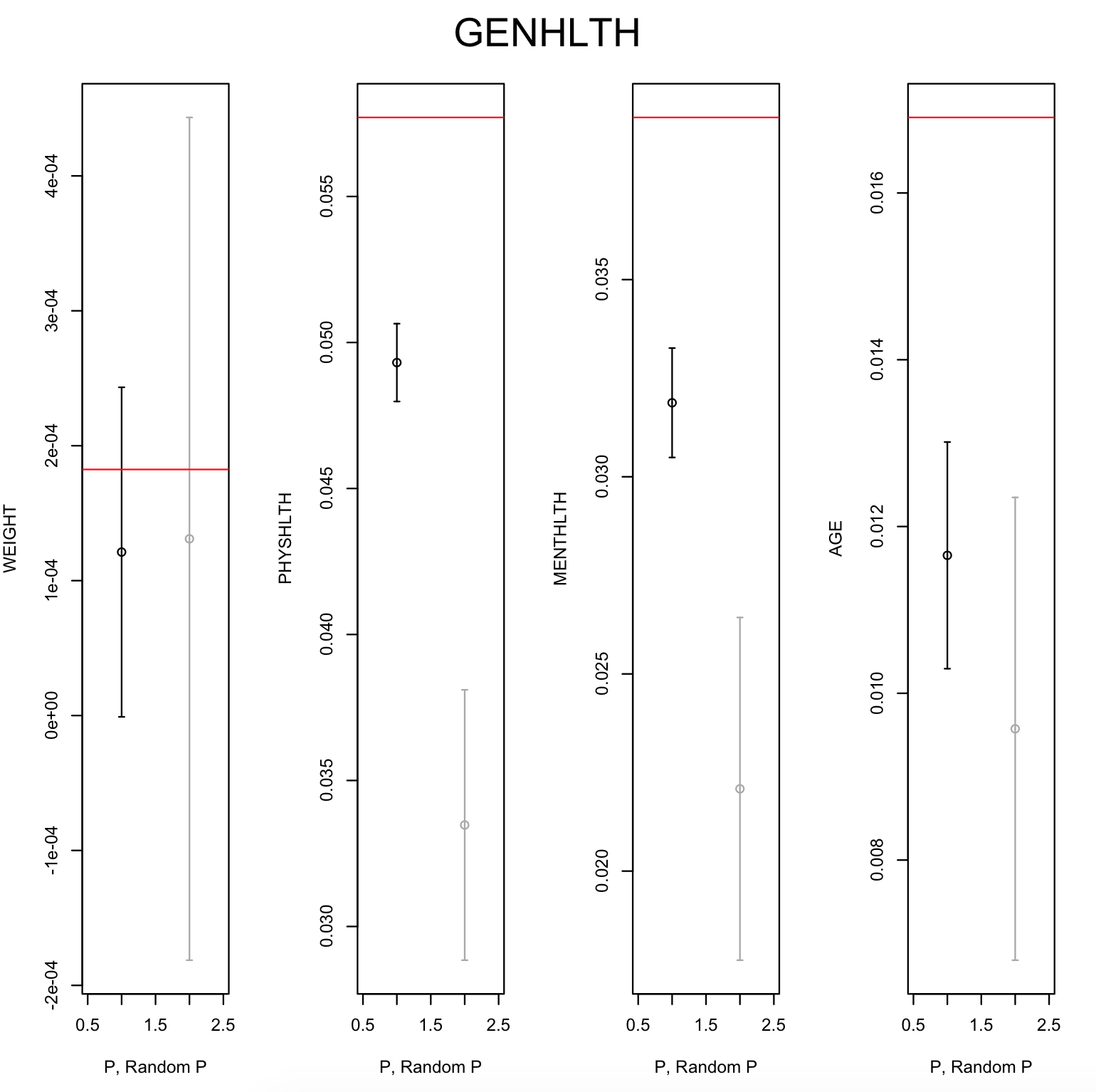
Existing file linkage methods may produce sub-optimal results because they consider neither the interactions between different pairs of matched records nor relationships between variables that are exclusive to one of the files. In addition, many of the current methods fail to address the uncertainty in the linkage, which may result in overly precise estimates of relationships between variables that are exclusive to one of the files. Bayesian methods for record linkage can reduce the bias in the estimation of scientific relationships of interest and provide interval estimates that account for the uncertainty in the linkage; however, implementation of these methods can often be complex and computationally intensive. This article presents the GFS package for the R programming language that utilizes a Bayesian approach for file linkage. The linking procedure implemented in GFS samples from the joint posterior distribution of model parameters and the linking permutations. The algorithm approaches file linkage as a missing data problem and generates multiple linked data sets. For computational efficiency, only the linkage permutations are stored and multiple analyses are performed using each of the permutations separately. This implementation reduces the computational complexity of the linking process and the expertise required of researchers analyzing linked data sets. We describe the algorithm implemented in the GFS package and its statistical basis, and demonstrate its use on a sample data set.
翻译:现有文件链接方法可能产生亚最佳结果,因为它们既未考虑到不同对应记录之间的相互作用,也未考虑到不同对应记录之间的相互作用,也未考虑到一个文件所独有的变量之间的关系。此外,许多现行方法未能解决联系的不确定性,这可能导致对一个文件所独有的变量之间的关系作出过于精确的估计。巴伊斯记录链接方法可以减少在估计科学关系中存在偏差的情况,并提供计算关联不确定性的间隔估计;然而,这些方法的实施往往很复杂,且在计算上十分密集。本文章介绍了使用巴伊西亚方法进行文件链接的R编程语言的GFS软件包。在GFS样本中执行的链接程序,该样本来自模型参数的联合远端分布和连接。算法方法将链接作为缺失的数据问题归档,生成多个链接数据集。对于计算效率而言,只有链接的存储和多次分析才能分别使用这些拼图进行。这一应用减少了链接过程的计算复杂性,以及研究人员分析链接数据集所需的专门知识。我们介绍了在GFS软件包中采用的算法,并展示了其数据集。