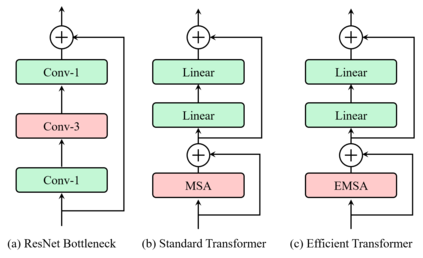
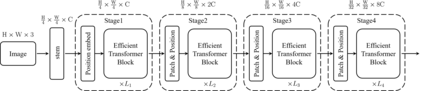
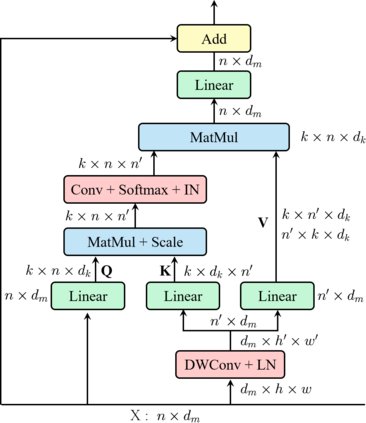
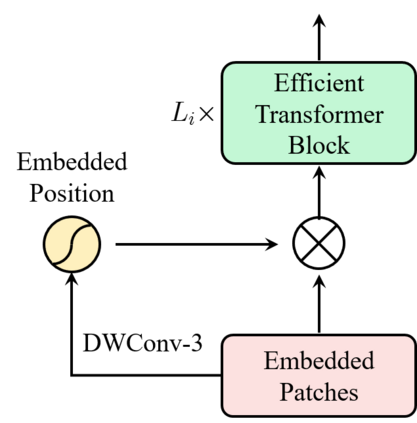
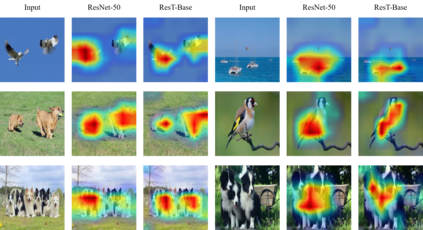
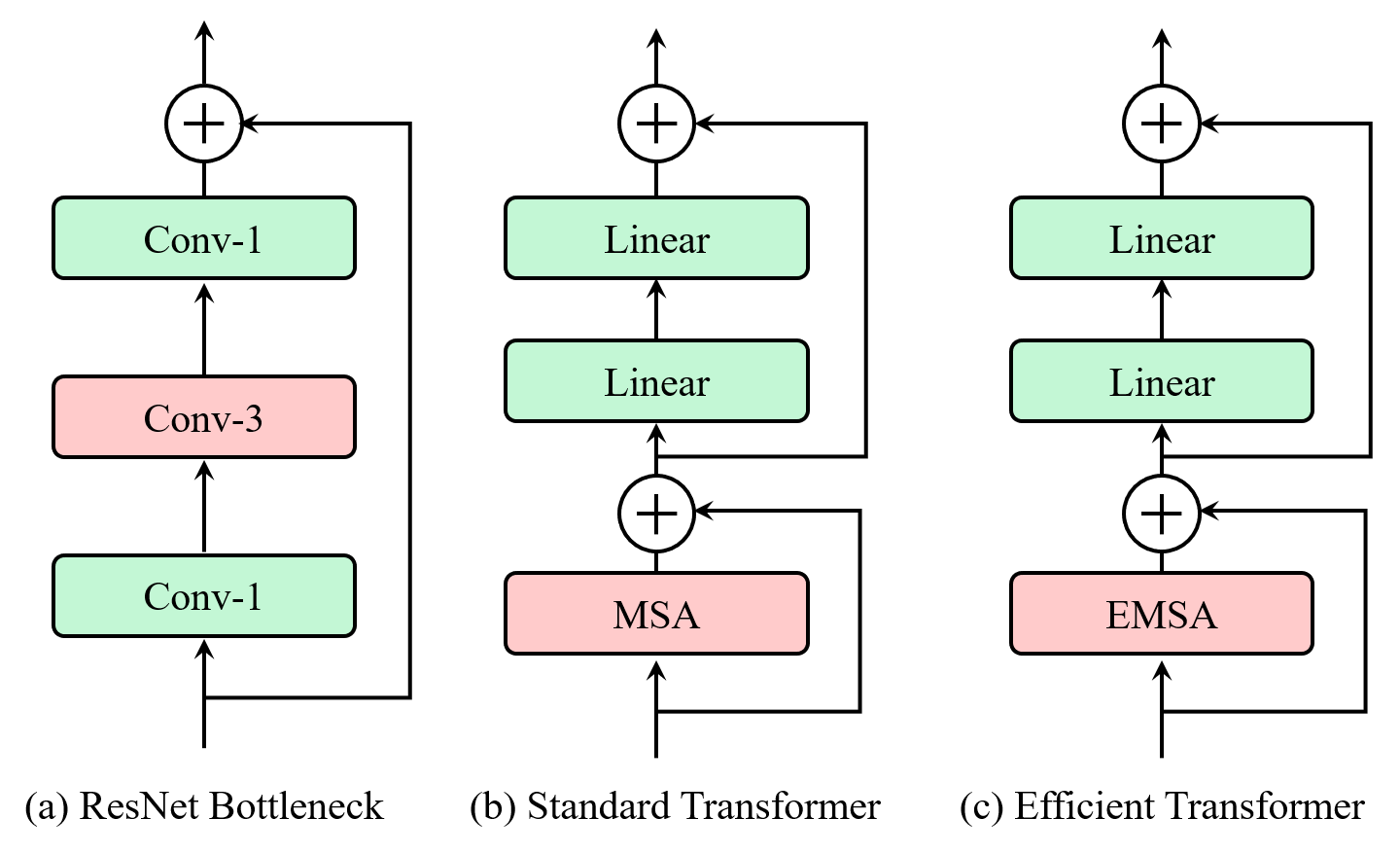
This paper presents an efficient multi-scale vision Transformer, called ResT, that capably served as a general-purpose backbone for image recognition. Unlike existing Transformer methods, which employ standard Transformer blocks to tackle raw images with a fixed resolution, our ResT have several advantages: (1) A memory-efficient multi-head self-attention is built, which compresses the memory by a simple depth-wise convolution, and projects the interaction across the attention-heads dimension while keeping the diversity ability of multi-heads; (2) Position encoding is constructed as spatial attention, which is more flexible and can tackle with input images of arbitrary size without interpolation or fine-tune; (3) Instead of the straightforward tokenization at the beginning of each stage, we design the patch embedding as a stack of overlapping convolution operation with stride on the 2D-reshaped token map. We comprehensively validate ResT on image classification and downstream tasks. Experimental results show that the proposed ResT can outperform the recently state-of-the-art backbones by a large margin, demonstrating the potential of ResT as strong backbones. The code and models will be made publicly available at https://github.com/wofmanaf/ResT.
翻译:本文展示了高效的多尺度视觉变异器,称为ResT,可以作为一般目的的图像识别骨干。与现有的变异器方法不同,这些变异器使用标准的变异器块来用固定分辨率处理原始图像,我们的变异器具有若干优点:(1) 构建了记忆效率高的多头自省,通过简单的深度演化压缩记忆力,并预测了注意力偏头的交互作用,同时保持了多头多头的多样化能力;(2) 定位编码是作为空间关注而构建的,它更灵活,能够以任意大小的输入图像处理,而没有内插或微调;(3) 与每个阶段的直截面符号化不同,我们将补丁设计成一组重叠的变异操作,在 2D 变形符号图上标注。我们全面验证关于图像分类和下游任务的ResT。 实验结果表明,拟议的ResT能够以大边距超越最近的状态的骨架,显示ResT作为坚固的脊的潜力。 代码和模型将公开在 http:// magif/ Resmax/ com上提供。