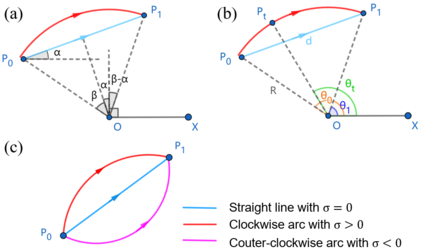
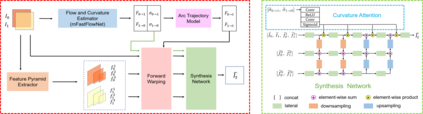
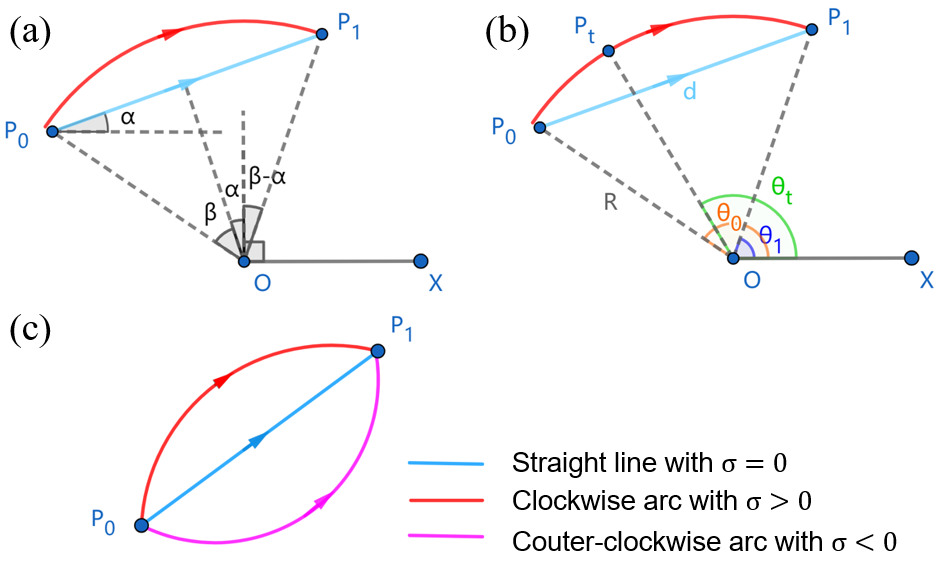
Video frame interpolation is a classic and challenging low-level computer vision task. Recently, deep learning based methods have achieved impressive results, and it has been proven that optical flow based methods can synthesize frames with higher quality. However, most flow-based methods assume a line trajectory with a constant velocity between two input frames. Only a little work enforces predictions with curvilinear trajectory, but this requires more than two frames as input to estimate the acceleration, which takes more time and memory to execute. To address this problem, we propose an arc trajectory based model (ATCA), which learns motion prior from only two consecutive frames and also is lightweight. Experiments show that our approach performs better than many SOTA methods with fewer parameters and faster inference speed.
翻译:视频框架的内插是一项经典且具有挑战性的低层次计算机愿景任务。 最近,基于深层次学习的方法取得了令人印象深刻的成果,并且已经证明光流法可以以更高质量合成框架。 然而,大多数基于流法都假设两个输入框架之间的直线轨迹。 只需要做一点小工作就可以执行具有曲线轨迹的预测,但这需要两个以上的框架作为计算加速度的输入,而加速度需要更多的时间和记忆才能执行。 为了解决这个问题,我们建议了一个以弧轨迹为基础的模型(ATCA ), 该模型只从两个连续的框中学习电动,并且也是轻量的。 实验显示,我们的方法比许多具有较少参数和更快推导速度的SOTA方法表现得更好。