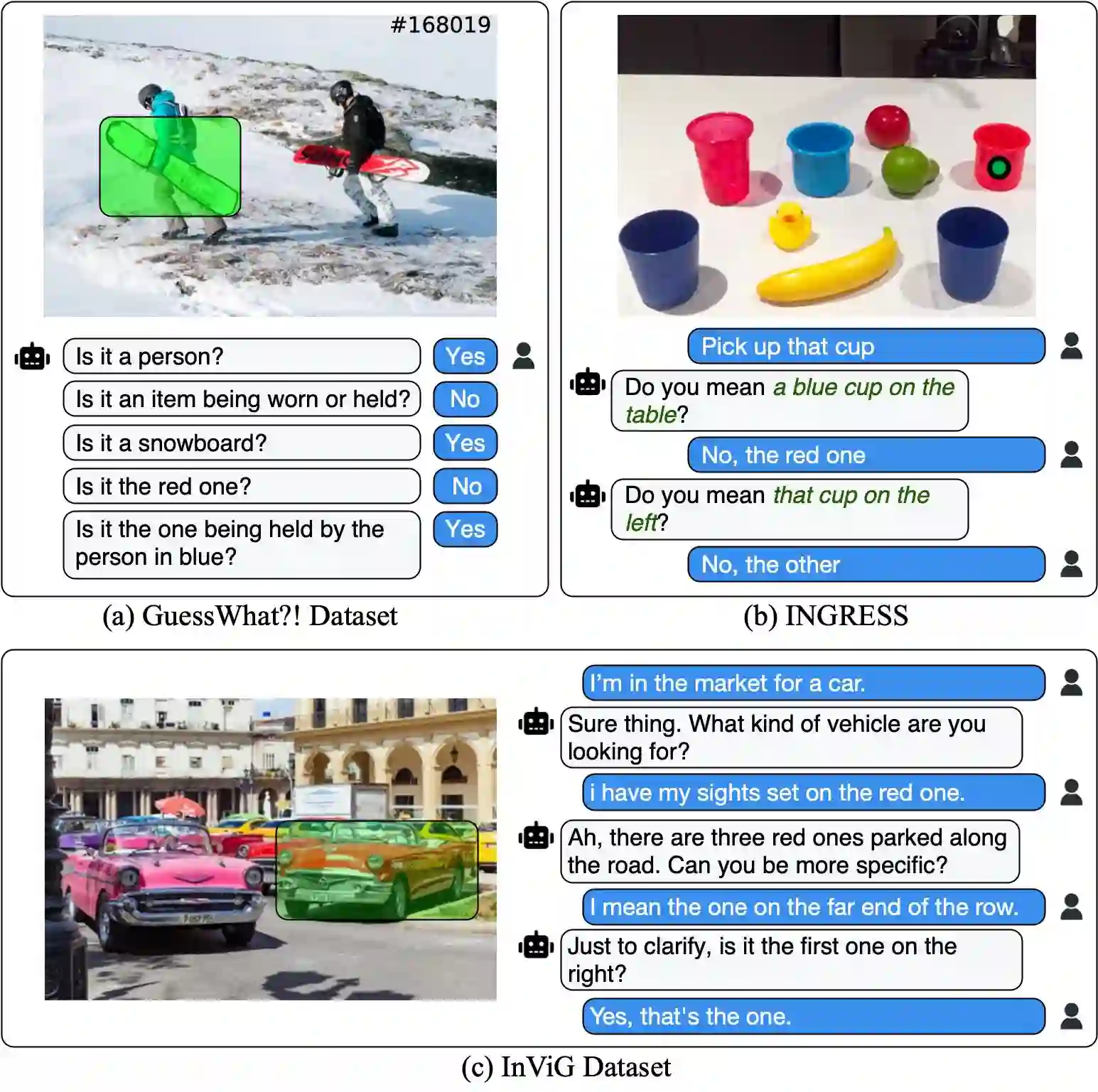
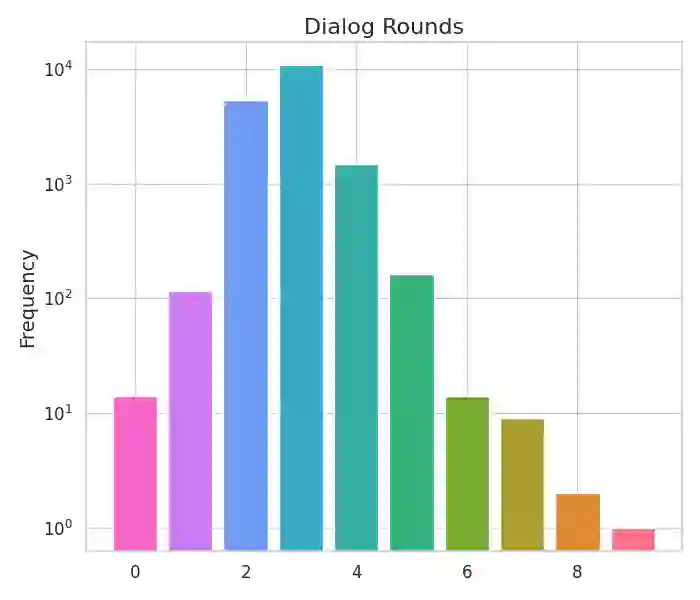
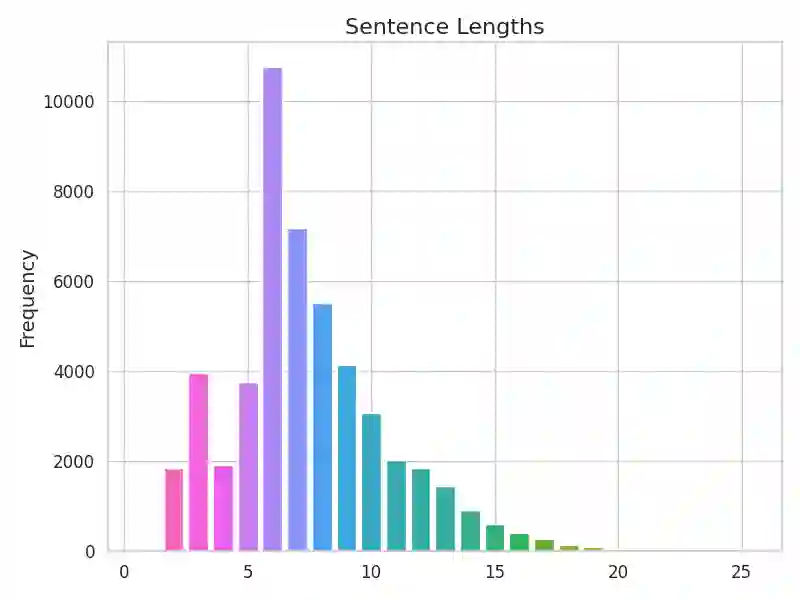
Ambiguity is ubiquitous in human communication. Previous approaches in Human-Robot Interaction (HRI) have often relied on predefined interaction templates, leading to reduced performance in realistic and open-ended scenarios. To address these issues, we present a large-scale dataset, \invig, for interactive visual grounding under language ambiguity. Our dataset comprises over 520K images accompanied by open-ended goal-oriented disambiguation dialogues, encompassing millions of object instances and corresponding question-answer pairs. Leveraging the \invig dataset, we conduct extensive studies and propose a set of baseline solutions for end-to-end interactive visual disambiguation and grounding, achieving a 45.6\% success rate during validation. To the best of our knowledge, the \invig dataset is the first large-scale dataset for resolving open-ended interactive visual grounding, presenting a practical yet highly challenging benchmark for ambiguity-aware HRI. Codes and datasets are available at: \href{https://openivg.github.io}{https://openivg.github.io}.
翻译:暂无翻译