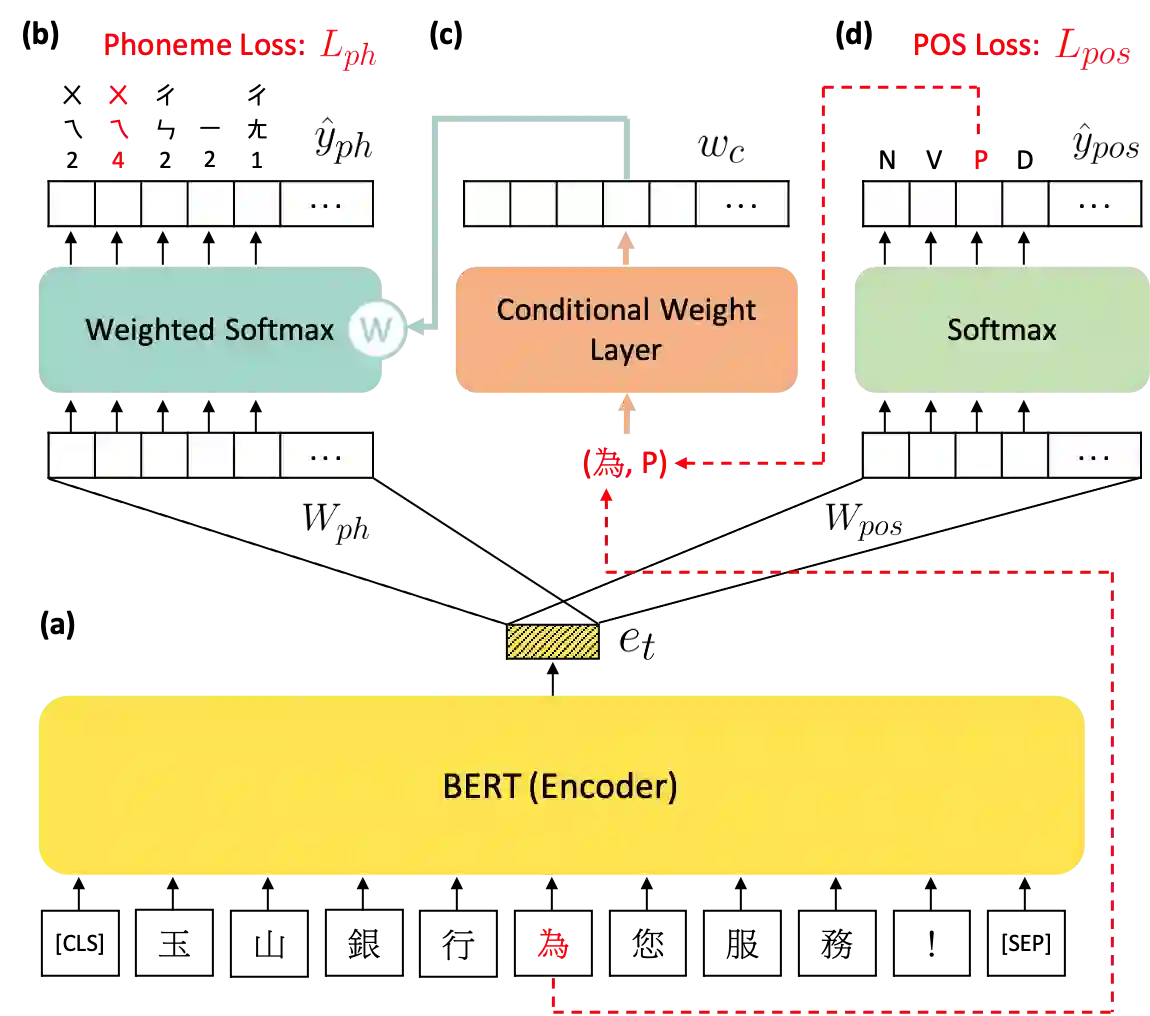
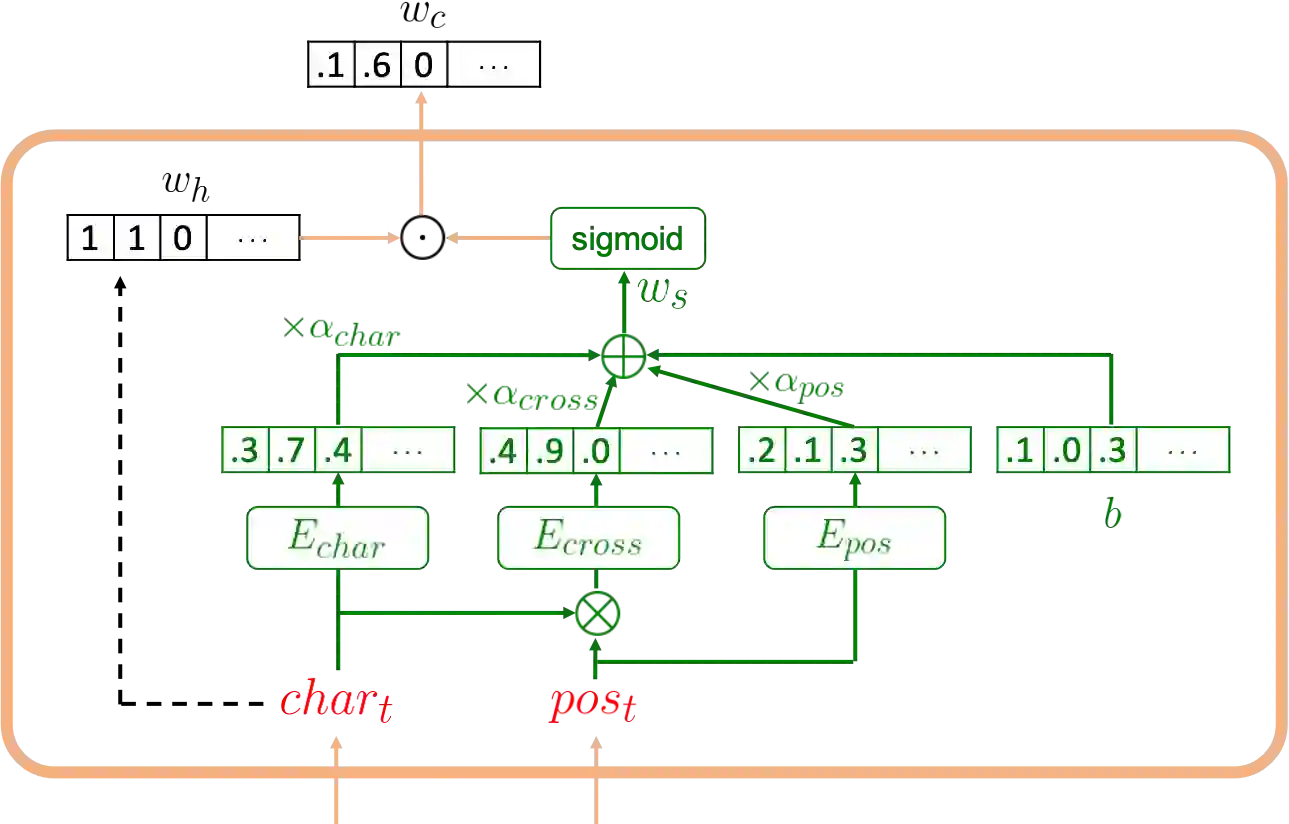
Polyphone disambiguation is the most crucial task in Mandarin grapheme-to-phoneme (g2p) conversion. Previous studies have approached this problem using pre-trained language models, restricted output, and extra information from Part-Of-Speech (POS) tagging. Inspired by these strategies, we propose a novel approach, called g2pW, which adapts learnable softmax-weights to condition the outputs of BERT with the polyphonic character of interest and its POS tagging. Rather than using the hard mask as in previous works, our experiments show that learning a soft-weighting function for the candidate phonemes benefits performance. In addition, our proposed g2pW does not require extra pre-trained POS tagging models while using POS tags as auxiliary features since we train the POS tagging model simultaneously with the unified encoder. Experimental results show that our g2pW outperforms existing methods on the public CPP dataset. All codes, model weights, and a user-friendly package are publicly available.
翻译:单声调脱钩是普通话语g2p( g2p) 转换中最重要的任务。 以前的研究已经使用预先培训的语言模型、 限制输出和来自部分语音标记的额外信息来解决这个问题。 受这些战略的启发, 我们提出了一个新颖的方法, 叫做 g2pW, 将可学习的软负负重量调整到使 BERT 的输出符合有兴趣的多功能特性及其 POS 标签。 我们的实验结果显示, 我们的 g2pW 超越了公共 CPP 数据集上的现有方法。 所有代码、 模型重量 和用户友好的软件都公开可用 。