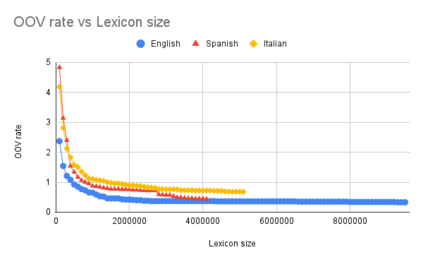
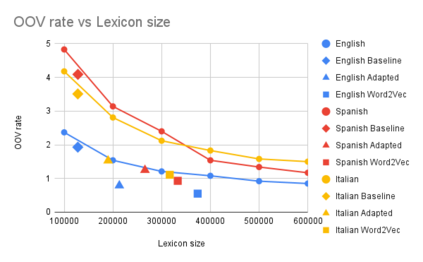
We address the problem of language model customization in applications where the ASR component needs to manage domain-specific terminology; although current state-of-the-art speech recognition technology provides excellent results for generic domains, the adaptation to specialized dictionaries or glossaries is still an open issue. In this work we present an approach for automatically selecting sentences, from a text corpus, that match, both semantically and morphologically, a glossary of terms (words or composite words) furnished by the user. The final goal is to rapidly adapt the language model of an hybrid ASR system with a limited amount of in-domain text data in order to successfully cope with the linguistic domain at hand; the vocabulary of the baseline model is expanded and tailored, reducing the resulting OOV rate. Data selection strategies based on shallow morphological seeds and semantic similarity viaword2vec are introduced and discussed; the experimental setting consists in a simultaneous interpreting scenario, where ASRs in three languages are designed to recognize the domain-specific terms (i.e. dentistry). Results using different metrics (OOV rate, WER, precision and recall) show the effectiveness of the proposed techniques.
翻译:在ASR组成部分需要管理特定领域术语的应用程序中,我们处理语言模式定制问题;虽然目前最先进的语音识别技术为通用领域提供了极好的结果,但对专门词典或词汇表的适应仍然是一个未决问题;在这项工作中,我们提出了一个从文字材料中自动选择句子的方法,这些句子在语义和形态上都与用户提供的术语词汇表(词词或复合词)相匹配,最终目标是迅速调整混合的ASR系统的语言模式,该系统的内流文本数据数量有限,以成功地应对手头的语言领域;基线模型的词汇被扩大和定制,从而减少由此产生的OOOVV比率;采用和讨论基于浅色形态种子的数据选择策略和通过文字2vec的语义相似性;试验设置包含一种同时解释情景,用三种语言设计ASR,以确认域特定术语(即牙医)。使用不同计量方法(OVES率、WER、精确度和回顾)的结果显示拟议技术的有效性。