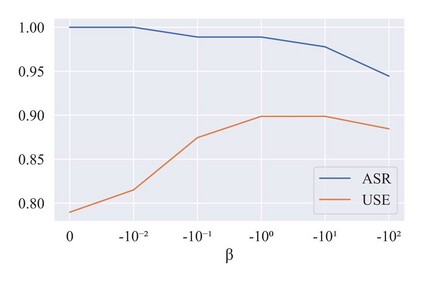
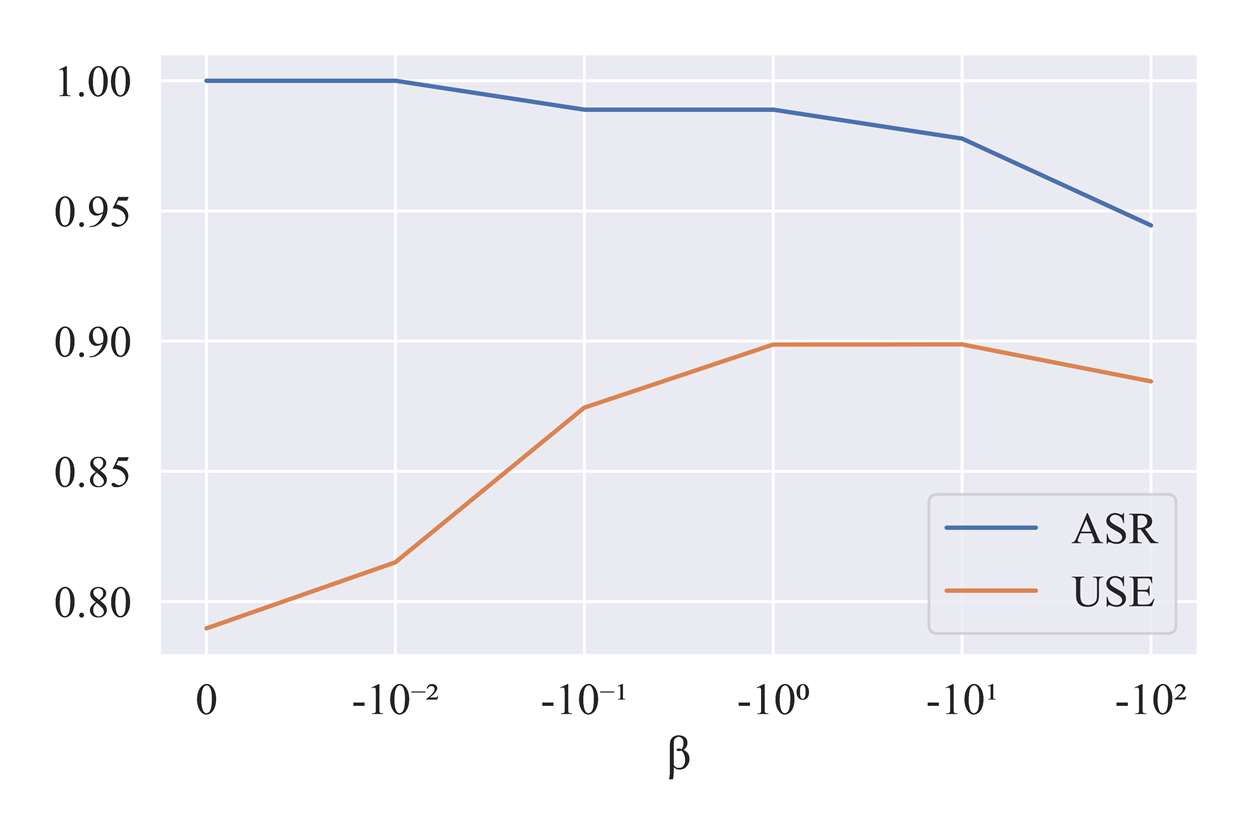
Despite recent success on various tasks, deep learning techniques still perform poorly on adversarial examples with small perturbations. While optimization-based methods for adversarial attacks are well-explored in the field of computer vision, it is impractical to directly apply them in natural language processing due to the discrete nature of the text. To address the problem, we propose a unified framework to extend the existing optimization-based adversarial attack methods in the vision domain to craft textual adversarial samples. In this framework, continuously optimized perturbations are added to the embedding layer and amplified in the forward propagation process. Then the final perturbed latent representations are decoded with a masked language model head to obtain potential adversarial samples. In this paper, we instantiate our framework with an attack algorithm named Textual Projected Gradient Descent (T-PGD). We find our algorithm effective even using proxy gradient information. Therefore, we perform the more challenging transfer black-box attack and conduct comprehensive experiments to evaluate our attack algorithm with several models on three benchmark datasets. Experimental results demonstrate that our method achieves an overall better performance and produces more fluent and grammatical adversarial samples compared to strong baseline methods. All the code and data will be made public.
翻译:尽管近来在各种任务上取得了成功,但深层次的学习技术仍然在对抗性实例方面表现不佳,而且受到小扰动。虽然在计算机视觉领域很好地探索了以优化为基础的对抗性攻击的最佳方法,但由于文本的离散性质,直接在自然语言处理中应用这些方法是不切实际的。为了解决这个问题,我们提议了一个统一框架,将视觉领域现有的以优化为基础的对抗性攻击方法扩大到设计文本对抗性样品。在这个框架内,在嵌入层中添加了持续优化的扰动,并在前方传播过程中放大了。随后,在最后的扰动性潜伏表层中用隐蔽语言模型头解码,以获得潜在的对抗性攻击性攻击样品。在本文件中,我们用名为“T-PGD”的攻击性算法将我们的框架立即应用称为“Textualual 预测梯子(T-PGD) ” 。我们发现我们的算法是有效的,即使使用代理性梯度信息。因此,我们进行更具挑战性的黑箱式转移式攻击,并进行全面实验,用三个基准数据集的几种模型来评价攻击性算算。实验结果表明我们的方法在总体上上取得了较好的业绩,并将产生较强的基线数据。比较。比较各种基准式的模型。比较。将采用较强的模型。