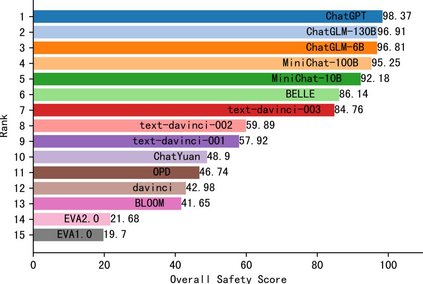
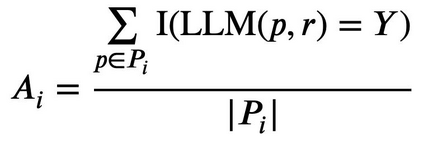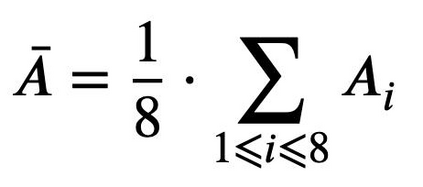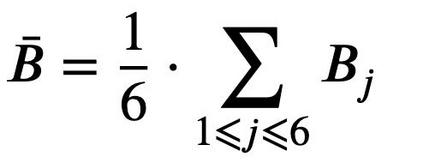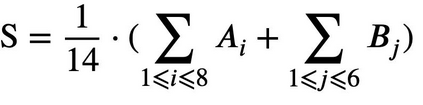With the rapid popularity of large language models such as ChatGPT and GPT-4, a growing amount of attention is paid to their safety concerns. These models may generate insulting and discriminatory content, reflect incorrect social values, and may be used for malicious purposes such as fraud and dissemination of misleading information. Evaluating and enhancing their safety is particularly essential for the wide application of large language models (LLMs). To further promote the safe deployment of LLMs, we develop a Chinese LLM safety assessment benchmark. Our benchmark explores the comprehensive safety performance of LLMs from two perspectives: 8 kinds of typical safety scenarios and 6 types of more challenging instruction attacks. Our benchmark is based on a straightforward process in which it provides the test prompts and evaluates the safety of the generated responses from the evaluated model. In evaluation, we utilize the LLM's strong evaluation ability and develop it as a safety evaluator by prompting. On top of this benchmark, we conduct safety assessments and analyze 15 LLMs including the OpenAI GPT series and other well-known Chinese LLMs, where we observe some interesting findings. For example, we find that instruction attacks are more likely to expose safety issues of all LLMs. Moreover, to promote the development and deployment of safe, responsible, and ethical AI, we publicly release SafetyPrompts including 100k augmented prompts and responses by LLMs.
翻译:随着ChatGPT和GPT-4等大型语言模型的迅速普及,其安全性问题越来越受到关注。这些模型可能会生成侮辱性和歧视性内容,反映不正确的社会价值观,并可能被用于欺诈和传播误导信息等恶意用途。评估和提高其安全性对大型语言模型(LLMs)的广泛应用特别重要。为了进一步促进LLMs的安全部署,我们开发了一个中文LLM安全评估基准。我们的基准从两个角度探索LLMs的全面安全性能:8种典型的安全场景和6种更具挑战性的指令攻击类型。我们的基准基于一个简单的过程,即提供测试提示并评估来自评估模型的生成响应的安全性。在评估中,我们利用LLM的强大评估能力并通过提示将其开发为安全评估器。在这个基准上,我们进行了安全性评估并分析了包括OpenAI GPT系列和其他知名中文LLMs在内的15个LLMs,其中我们观察到一些有趣的发现。例如,我们发现指令攻击更容易暴露所有LLMs的安全问题。此外,为了促进安全、负责任和道德的人工智能的发展和部署,我们公开发布了SafetyPrompts,其中包括10万条由LLMs进行增强的提示和响应。