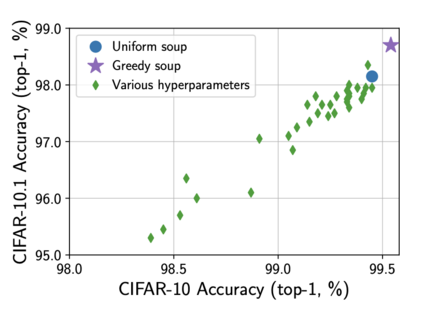
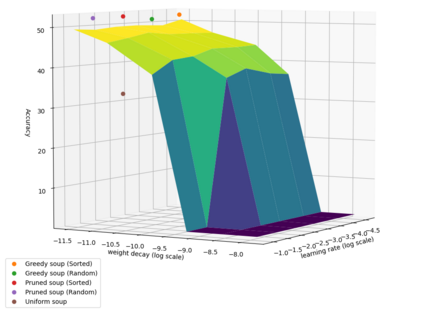
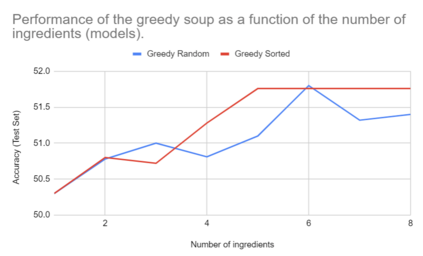
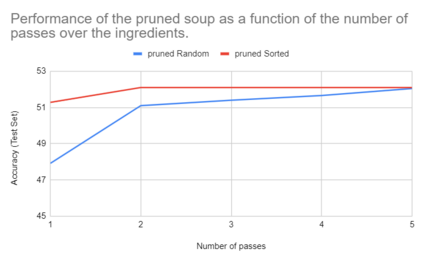
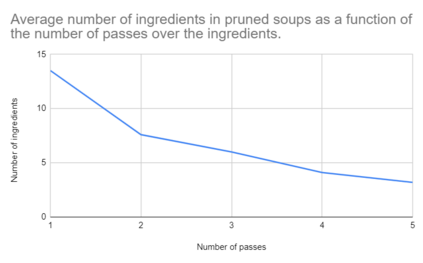
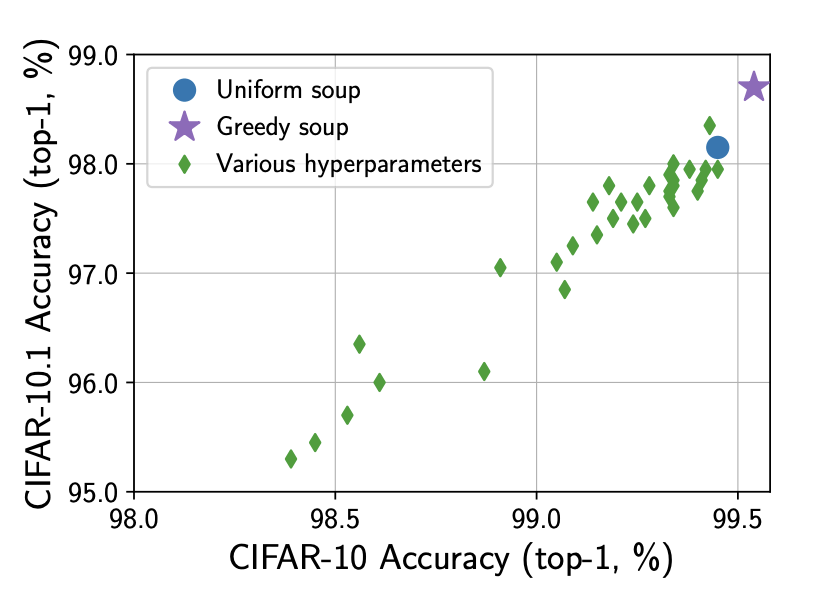
In this paper, we compare Model Soups performances on three different models (ResNet, ViT and EfficientNet) using three Soup Recipes (Greedy Soup Sorted, Greedy Soup Random and Uniform soup) from arXiv:2203.05482, and reproduce the results of the authors. We then introduce a new Soup Recipe called Pruned Soup. Results from the soups were better than the best individual model for the pre-trained vision transformer, but were much worst for the ResNet and the EfficientNet. Our pruned soup performed better than the uniform and greedy soups presented in the original paper. We also discuss the limitations of weight-averaging that were found during the experiments. The code for our model soup library and the experiments with different models can be found here: https://github.com/milo-sobral/ModelSoup
翻译:在本文中,我们比较了三种不同模型(ResNet、ViT、高效网络)的“模范苏普”表演,使用ArXiv:2203.05482的三种苏普(Greedy Soup Suproands and Aliver solution)的三种苏普(Greed Suple)食谱(Greedy Soup Suple)和ArXiv:2203.05482,并转载了作者的研究结果。然后我们推出了一个新的苏普鲁内德苏普(Pruned Soup)的新苏普(Sup)食谱。汤的效果比预先训练的视觉变压器的最佳个人模型要好,但对ResNet和高效网络来说却差得多。我们的纯汤比原始文件中的制服和贪婪汤做的要好。我们还讨论了实验中发现的体重保持的局限性。这里可以找到我们的示范汤库的代码和不同模型的实验: https://github.com/milo-sobral/ModelSoup)。