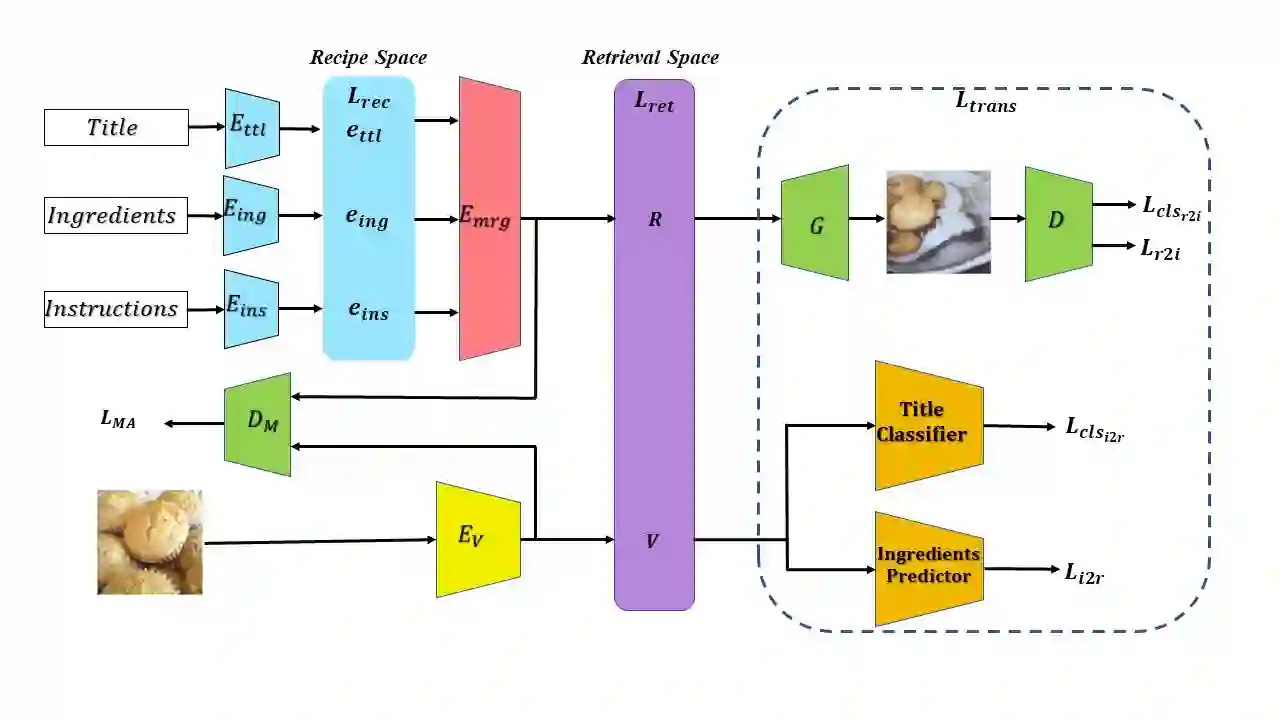
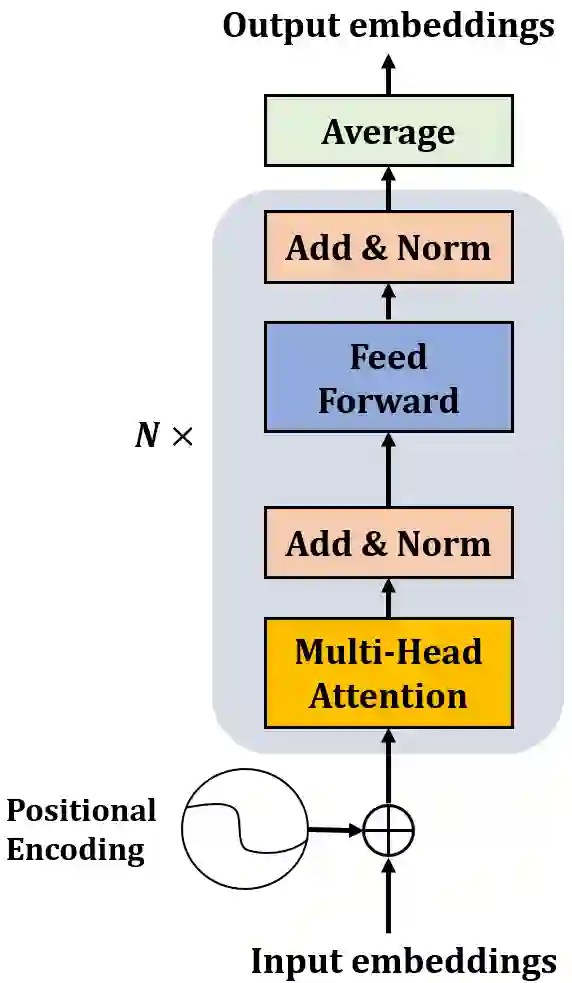
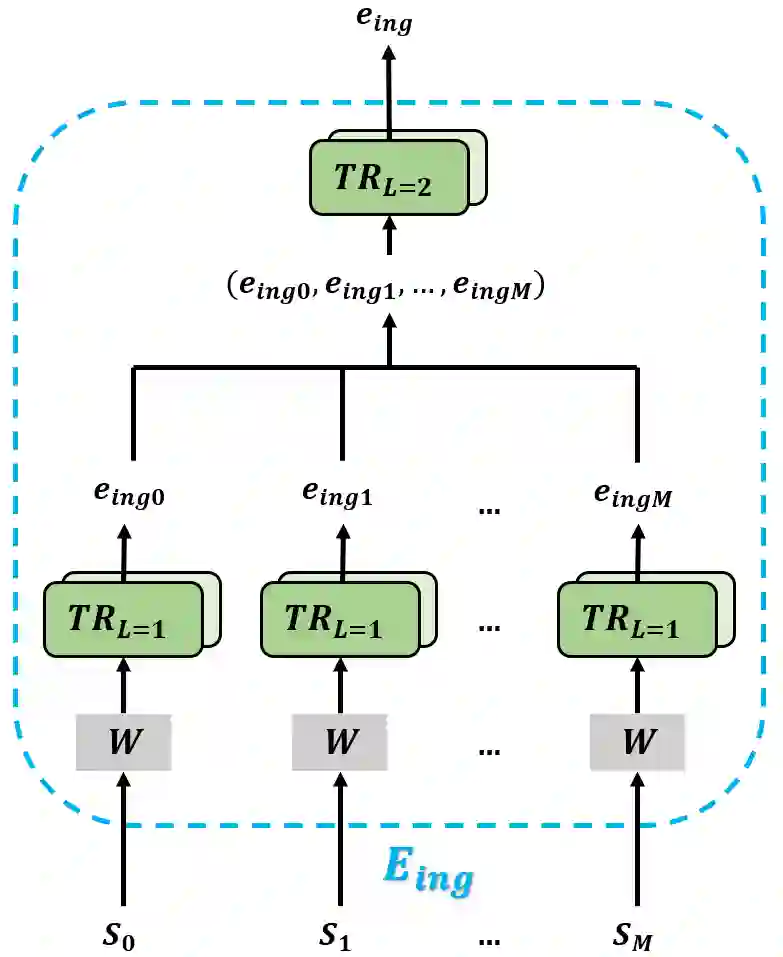
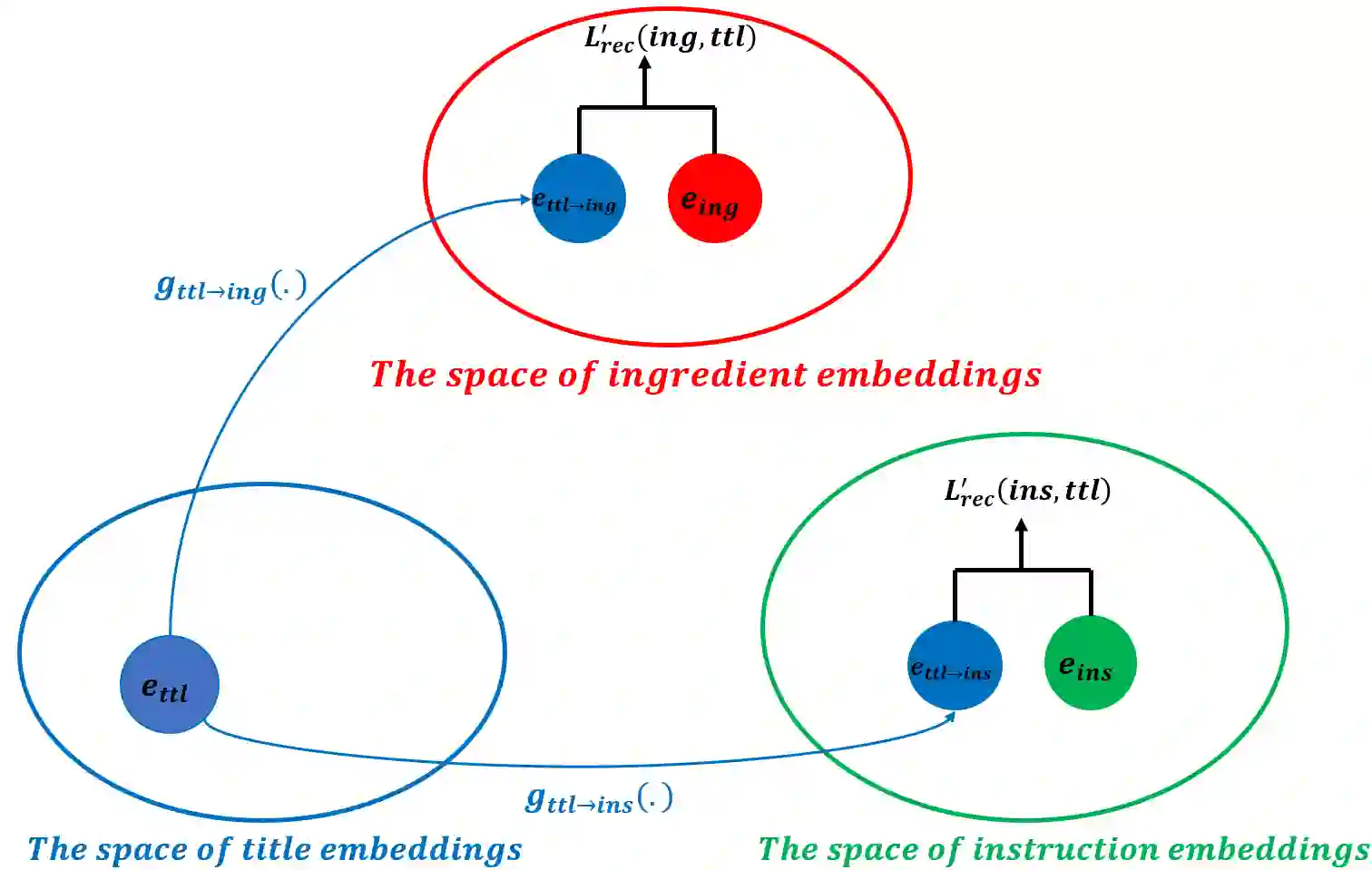
In this paper, we present a cross-modal recipe retrieval framework, Transformer-based Network for Large Batch Training (TNLBT), which is inspired by ACME~(Adversarial Cross-Modal Embedding) and H-T~(Hierarchical Transformer). TNLBT aims to accomplish retrieval tasks while generating images from recipe embeddings. We apply the Hierarchical Transformer-based recipe text encoder, the Vision Transformer~(ViT)-based recipe image encoder, and an adversarial network architecture to enable better cross-modal embedding learning for recipe texts and images. In addition, we use self-supervised learning to exploit the rich information in the recipe texts having no corresponding images. Since contrastive learning could benefit from a larger batch size according to the recent literature on self-supervised learning, we adopt a large batch size during training and have validated its effectiveness. In the experiments, the proposed framework significantly outperformed the current state-of-the-art frameworks in both cross-modal recipe retrieval and image generation tasks on the benchmark Recipe1M. This is the first work which confirmed the effectiveness of large batch training on cross-modal recipe embeddings.
翻译:在本文中,我们提出了一个跨模式食谱检索框架,即基于变压器的大批量培训网络(TNBCT),这是由ACME~(Adversarial Cross-Modal Embeding)和H-T~(H-Triarchic Trangerer)启发的。TNBCT的目的是完成检索任务,同时从配方嵌入图像。我们应用基于等级变压器的配方文本编码器、基于愿景变压器~(VYT)的配方图像编码器,以及一个有利于更好地为配方文本和图像进行跨模式嵌入学习的对抗性网络结构。此外,我们利用自我监督的学习来利用没有相应图像的配方文本中的丰富信息。由于对比性学习可以受益于根据最近关于自我监督学习的文献的较大批量的批量,我们在培训中采用了大批量的配方文本,并验证了其有效性。在实验中,拟议框架大大超越了交叉配方食谱检索和图像生成的当前状态框架。这是关于基准 Reip1M的大规模嵌入的首批确认性培训。