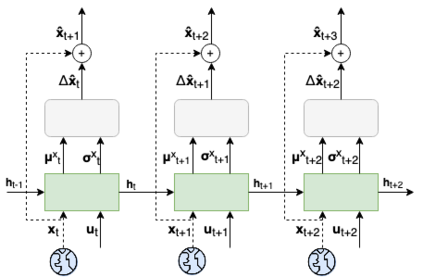
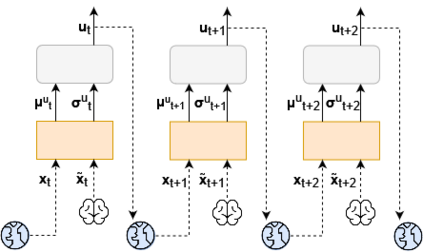
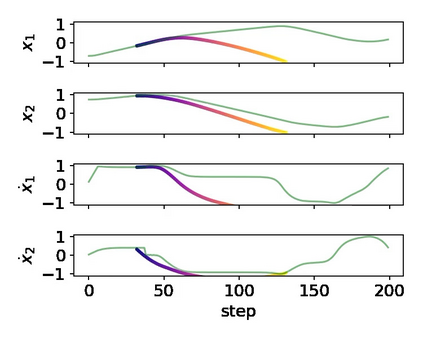
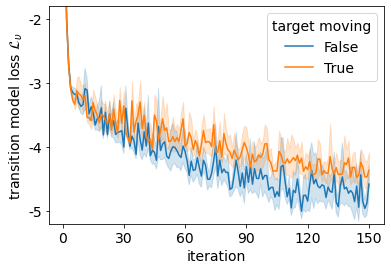
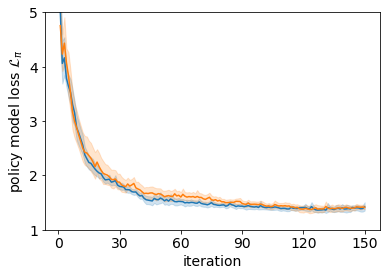
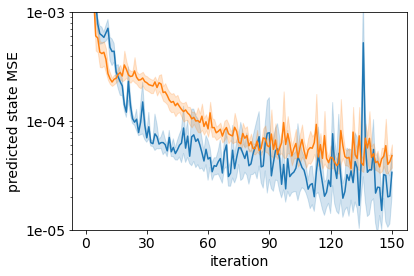
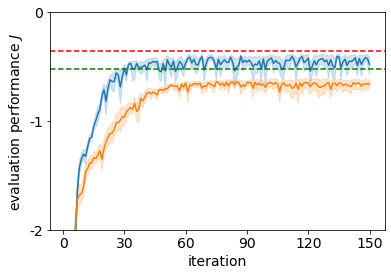
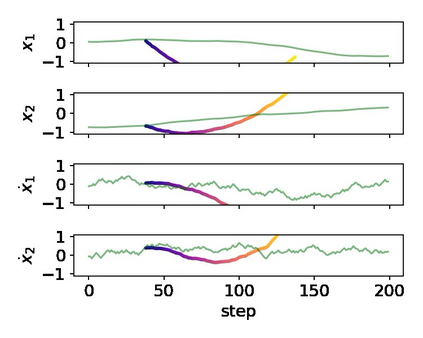
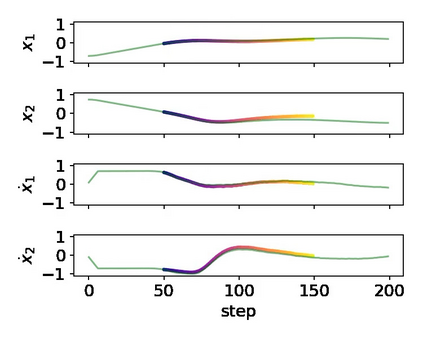
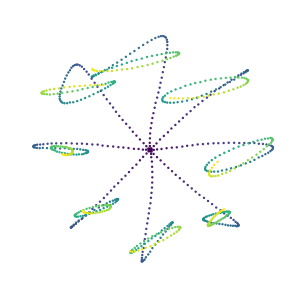
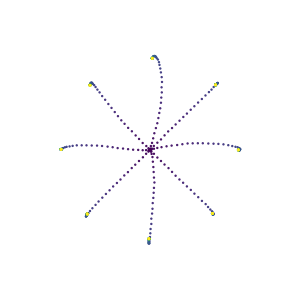
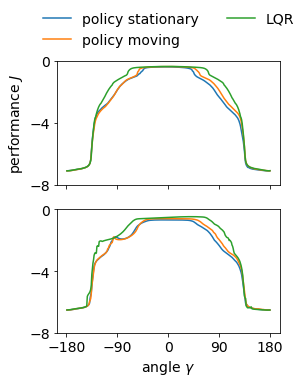
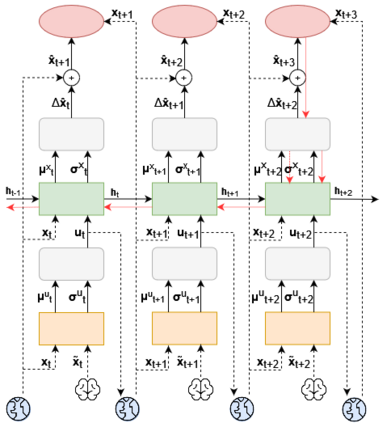
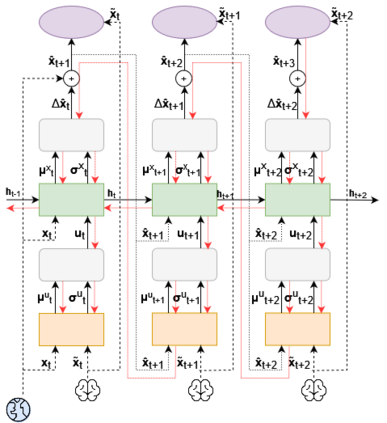
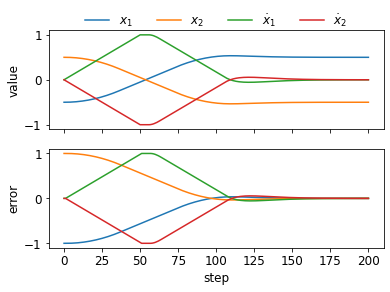
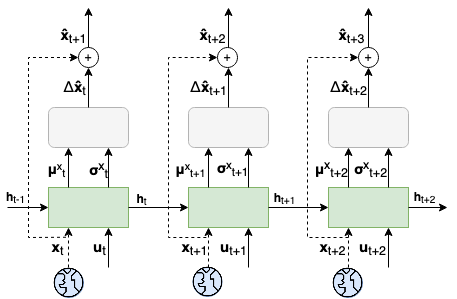
It is doubtful that animals have perfect inverse models of their limbs (e.g., what muscle contraction must be applied to every joint to reach a particular location in space). However, in robot control, moving an arm's end-effector to a target position or along a target trajectory requires accurate forward and inverse models. Here we show that by learning the transition (forward) model from interaction, we can use it to drive the learning of an amortized policy. Hence, we revisit policy optimization in relation to the deep active inference framework and describe a modular neural network architecture that simultaneously learns the system dynamics from prediction errors and the stochastic policy that generates suitable continuous control commands to reach a desired reference position. We evaluated the model by comparing it against the baseline of a linear quadratic regulator, and conclude with additional steps to take toward human-like motor control.
翻译:动物的四肢有完美的反向模型(例如,肌肉收缩必须适用于每一关节,才能到达空间的特定位置)是值得怀疑的。 然而,在机器人控制中,将手臂的末效器移动到目标位置或沿着目标轨道需要准确的前向和反向模型。 我们在这里通过从互动中学习过渡(前向)模型来显示,我们可以通过它来推动分解政策的学习。 因此,我们重新审视与深度主动推断框架有关的政策优化,并描述一个模块式神经网络结构,该结构同时从预测错误和产生合适的连续控制命令以达到理想参考位置的随机政策中学习系统动态。我们通过将模型与线形四极调节器的基准进行比较来评估模型,并最后采取更多步骤,以转向人型运动控制。