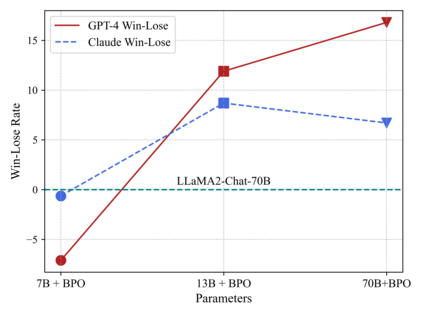
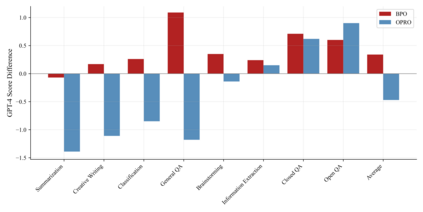
Large language models (LLMs) have shown impressive success in various applications. However, these models are often not well aligned with human intents, which calls for additional treatments on them, that is, the alignment problem. To make LLMs better follow user instructions, existing alignment methods mostly focus on further training them. However, the extra training of LLMs are usually expensive in terms of GPU compute; worse still, LLMs of interest are oftentimes not accessible for user-demanded training, such as GPTs. In this work, we take a different perspective -- Black-Box Prompt Optimization (BPO) -- to perform alignments. The idea is to optimize user prompts to suit LLMs' input understanding, so as to best realize users' intents without updating LLMs' parameters. BPO is model-agnostic and the empirical results demonstrate that the BPO-aligned ChatGPT yields a 22\% increase in the win rate against its original version, and 10\% for GPT-4. Importantly, the \model-aligned LLMs can outperform the same models aligned by PPO and DPO, and it also brings additional performance gains when combining \model with PPO or DPO. Code and datasets are released at https://github.com/thu-coai/BPO.
翻译:暂无翻译