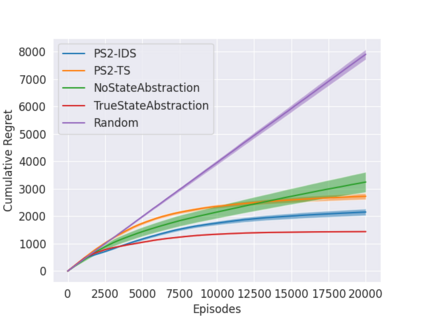
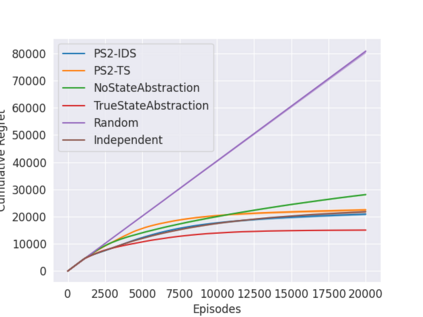
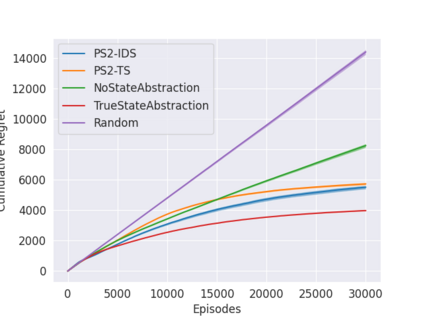
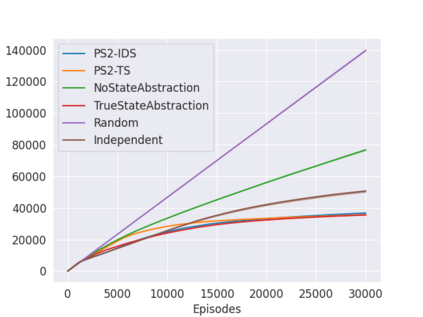
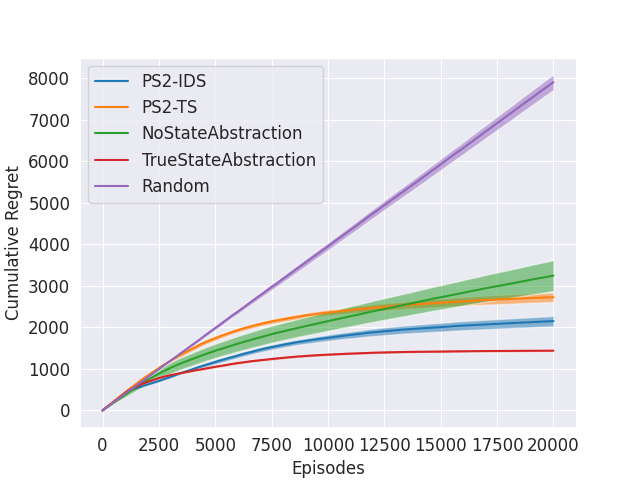
State abstraction has been an essential tool for dramatically improving the sample efficiency of reinforcement-learning algorithms. Indeed, by exposing and accentuating various types of latent structure within the environment, different classes of state abstraction have enabled improved theoretical guarantees and empirical performance. When dealing with state abstractions that capture structure in the value function, however, a standard assumption is that the true abstraction has been supplied or unrealistically computed a priori, leaving open the question of how to efficiently uncover such latent structure while jointly seeking out optimal behavior. Taking inspiration from the bandit literature, we propose that an agent seeking out latent task structure must explicitly represent and maintain its uncertainty over that structure as part of its overall uncertainty about the environment. We introduce a practical algorithm for doing this using two posterior distributions over state abstractions and abstract-state values. In empirically validating our approach, we find that substantial performance gains lie in the multi-task setting where tasks share a common, low-dimensional representation.
翻译:国家抽象学是大幅提高强化学习算法抽样效率的重要工具。 事实上,通过揭露和强化环境中各种潜在结构,不同等级的国家抽象学能够改善理论保障和经验表现。 然而,在处理反映价值函数结构的国家抽象学时,一个标准假设是,真正的抽象学已经提供,或者事先不切实际地计算,在共同寻求最佳行为的同时,如何有效发现这种潜在结构的问题尚未解决。我们从强盗文献中得到的启发,建议寻找潜在任务结构的代理人必须明确代表并保持其对该结构的不确定性,作为环境总体不确定性的一部分。我们采用了一种实用算法,用两种远地点分布取代国家抽象和抽象国家价值。在实证性地证明我们的方法时,我们发现在确定任务具有共同、低维度代表性的多任务时,可以产生实质性的绩效收益。