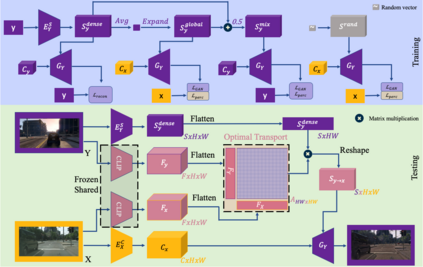
Unpaired exemplar-based image-to-image (UEI2I) translation aims to translate a source image to a target image domain with the style of a target image exemplar, without ground-truth input-translation pairs. Existing UEI2I methods represent style using either a global, image-level feature vector, or one vector per object instance/class but requiring knowledge of the scene semantics. Here, by contrast, we propose to represent style as a dense feature map, allowing for a finer-grained transfer to the source image without requiring any external semantic information. We then rely on perceptual and adversarial losses to disentangle our dense style and content representations, and exploit unsupervised cross-domain semantic correspondences to warp the exemplar style to the source content. We demonstrate the effectiveness of our method on two datasets using standard metrics together with a new localized style metric measuring style similarity in a class-wise manner. Our results evidence that the translations produced by our approach are more diverse and closer to the exemplars than those of the state-of-the-art methods while nonetheless preserving the source content.
翻译:未经映射的图像到映像( UEI2I) 翻译的目的是将源图像转换成目标图像域,使用目标图像的风格,不使用地面真实输入翻译配对。 现有的 UEI2I 方法代表了一种风格, 使用全球的图像级特性矢量, 或每个对象的矢量, 或一个矢量, 但需要了解现场语义学。 相反, 我们提议将风格表现为一种密集的特征映像( UEI2I), 允许在不要求任何外部语义信息的情况下, 将原始图像转换为源图像。 我们随后依靠感知性和对抗性损失来分解我们稠密的风格和内容表达方式, 并利用不受监督的跨部语义对应, 将光度样式对源内容进行扭曲。 我们用标准度来展示我们两个数据集的方法的有效性, 并用一种新的本地风格测量样式测量风格, 以类比方式测量风格。 我们的翻译结果证明我们的方法所制作的翻译更加多样化, 更接近演示源中的数据。