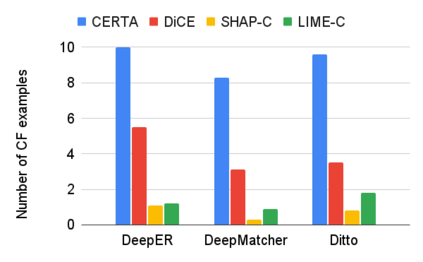
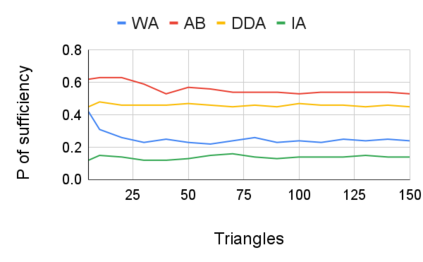
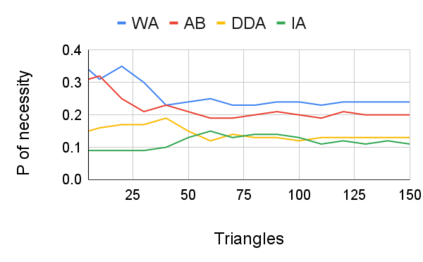
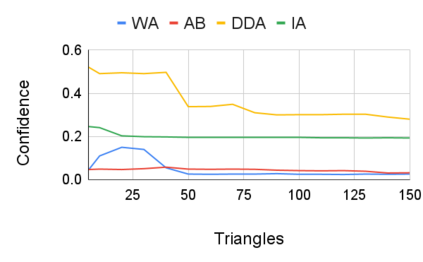
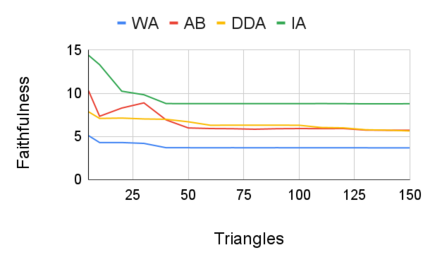
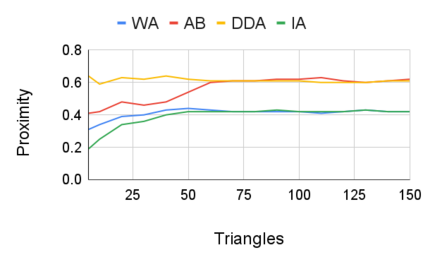
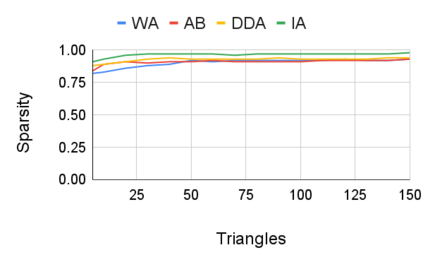
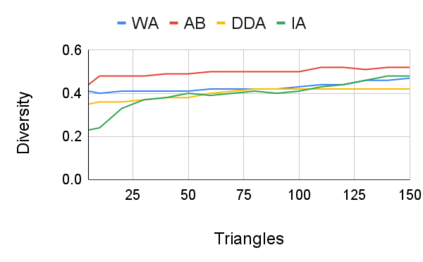
Entity resolution (ER) aims at matching records that refer to the same real-world entity. Although widely studied for the last 50 years, ER still represents a challenging data management problem, and several recent works have started to investigate the opportunity of applying deep learning (DL) techniques to solve this problem. In this paper, we study the fundamental problem of explainability of the DL solution for ER. Understanding the matching predictions of an ER solution is indeed crucial to assess the trustworthiness of the DL model and to discover its biases. We treat the DL model as a black box classifier and - while previous approaches to provide explanations for DL predictions are agnostic to the classification task. we propose the CERTA approach that is aware of the semantics of the ER problem. Our approach produces both saliency explanations, which associate each attribute with a saliency score, and counterfactual explanations, which provide examples of values that can flip the prediction. CERTA builds on a probabilistic framework that aims at computing the explanations evaluating the outcomes produced by using perturbed copies of the input records. We experimentally evaluate CERTA's explanations of state-of-the-art ER solutions based on DL models using publicly available datasets, and demonstrate the effectiveness of CERTA over recently proposed methods for this problem.
翻译:实体分辨率( ER) 旨在匹配提及同一真实世界实体的记录。 尽管过去50年来已经广泛研究过, ER仍然代表着一个具有挑战性的数据管理问题, 最近的一些工作已经开始调查应用深学习(DL)技术解决这一问题的机会。 在本文件中, 我们研究了ERDL解决方案的解释性的根本问题。 了解ER解决方案的匹配预测对于评估DL模型的可信度并发现其偏差确实至关重要。 我们把DL模型作为黑盒分类器对待, 并且 - 尽管以前为DL预测提供解释的方法对于分类任务来说是不可知的。 我们提出了CERTA方法, 了解ER问题的精度。 我们的方法既提出了突出的解释, 将每个属性与显著的分数联系起来, 也提出了反事实解释, 提供了能够推翻预测的数值的例子。 CERTA 建立在一种预测性框架之上, 目的是计算通过使用输入记录每张的拷贝来评估结果的解释。 我们用CERTARA的现有数据方法对基于最新数据方法的模型进行试验性评估。