
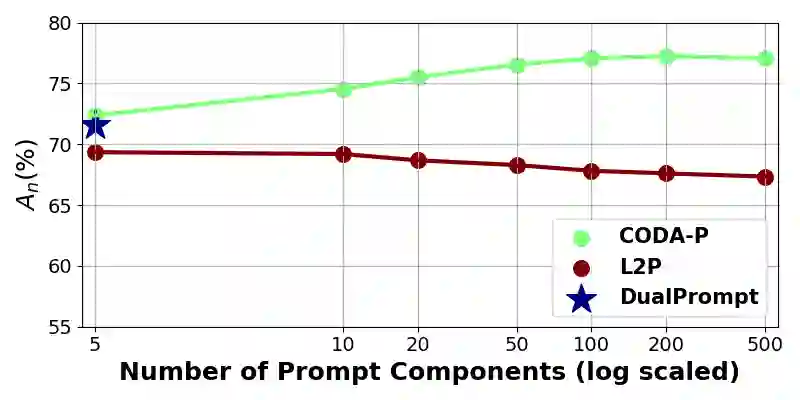
Computer vision models suffer from a phenomenon known as catastrophic forgetting when learning novel concepts from continuously shifting training data. Typical solutions for this continual learning problem require extensive rehearsal of previously seen data, which increases memory costs and may violate data privacy. Recently, the emergence of large-scale pre-trained vision transformer models has enabled prompting approaches as an alternative to data-rehearsal. These approaches rely on a key-query mechanism to generate prompts and have been found to be highly resistant to catastrophic forgetting in the well-established rehearsal-free continual learning setting. However, the key mechanism of these methods is not trained end-to-end with the task sequence. Our experiments show that this leads to a reduction in their plasticity, hence sacrificing new task accuracy, and inability to benefit from expanded parameter capacity. We instead propose to learn a set of prompt components which are assembled with input-conditioned weights to produce input-conditioned prompts, resulting in a novel attention-based end-to-end key-query scheme. Our experiments show that we outperform the current SOTA method DualPrompt on established benchmarks by as much as 5.4% in average accuracy. We also outperform the state of art by as much as 6.6% accuracy on a continual learning benchmark which contains both class-incremental and domain-incremental task shifts, corresponding to many practical settings.
翻译:计算机愿景模型存在一个被称作“灾难性的遗忘”现象,因为从不断改变的培训数据中学习新概念时,人们会从不断改变的培训数据中发现“灾难性的遗忘”现象。这一持续学习问题的典型解决办法需要大量练习以往看到的数据,这增加了记忆成本,并可能侵犯数据隐私。最近,大规模预先培训的愿景变异模型的出现使得能够采取快速方法,替代数据再演练。这些方法依靠关键查询机制产生提示,发现在完善的无排练持续学习环境中,对灾难性的遗忘非常抵制。然而,这些方法的关键机制没有在任务序列中经过端至端的培训。我们的实验表明,这导致其可塑性下降,从而牺牲新的任务准确性,无法从扩大参数能力中受益。我们提议学习一套快速的组件,这些组件由输入附加条件的重量组成,以产生基于投入的提示的提示,从而形成一种新的基于关注端到端不间断的关键que方法。我们的实验显示,我们超越了当前SATA方法在既定基准上的端端到端到端到端。我们的实验显示,在平均精确度中,5.4 %中,我们还以连续的准确性方向的精确性地将6.3级的精确性任务设置置于一个连续的状态。我们作为相同的基准。



相关内容

Source: Apple - iOS 8

