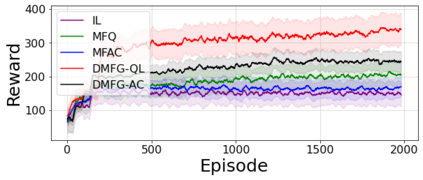
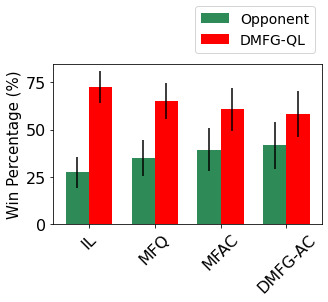
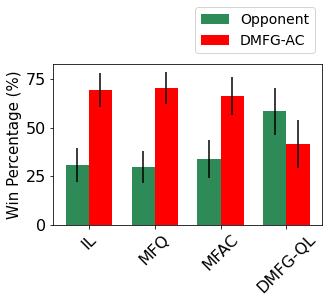
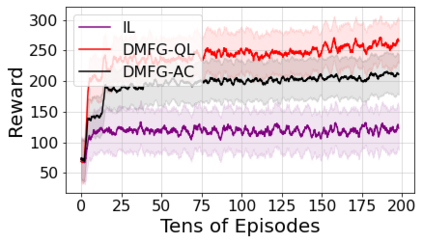
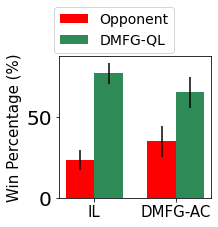
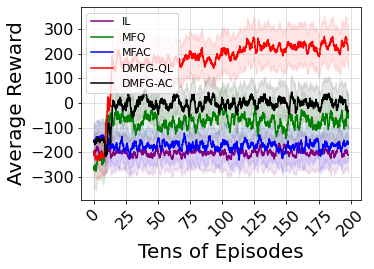
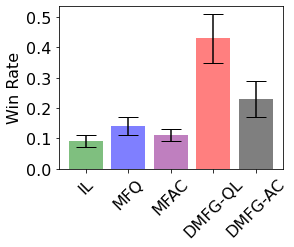
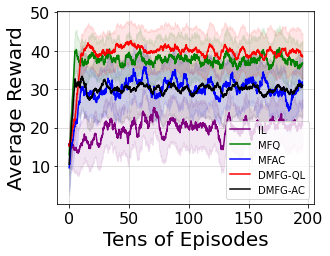
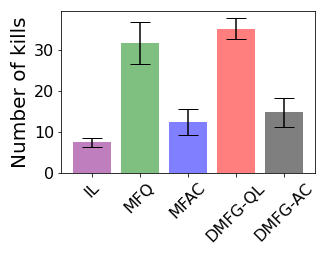
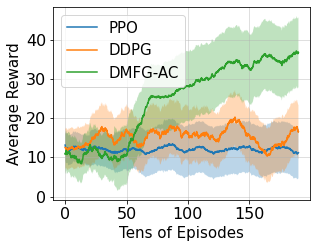
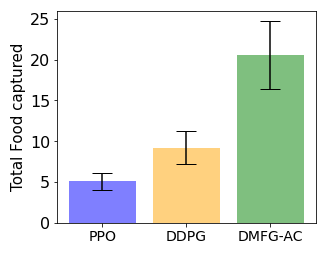
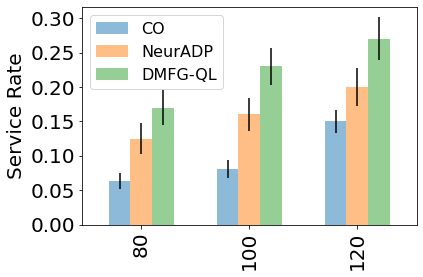
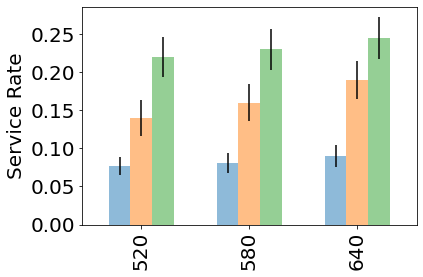
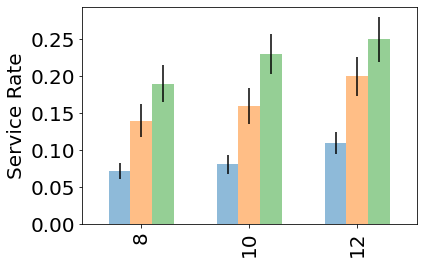
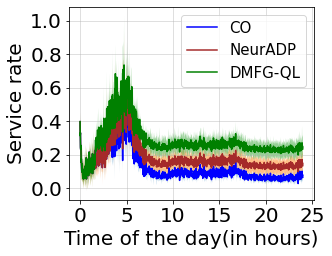
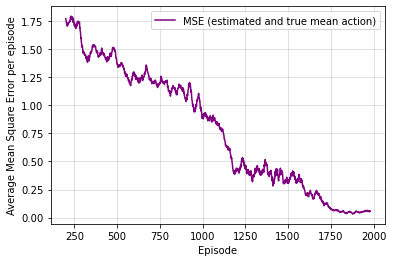
Multiagent reinforcement learning algorithms have not been widely adopted in large scale environments with many agents as they often scale poorly with the number of agents. Using mean field theory to aggregate agents has been proposed as a solution to this problem. However, almost all previous methods in this area make a strong assumption of a centralized system where all the agents in the environment learn the same policy and are effectively indistinguishable from each other. In this paper, we relax this assumption about indistinguishable agents and propose a new mean field system known as Decentralized Mean Field Games, where each agent can be quite different from others. All agents learn independent policies in a decentralized fashion, based on their local observations. We define a theoretical solution concept for this system and provide a fixed point guarantee for a Q-learning based algorithm in this system. A practical consequence of our approach is that we can address a `chicken-and-egg' problem in empirical mean field reinforcement learning algorithms. Further, we provide Q-learning and actor-critic algorithms that use the decentralized mean field learning approach and give stronger performances compared to common baselines in this area. In our setting, agents do not need to be clones of each other and learn in a fully decentralized fashion. Hence, for the first time, we show the application of mean field learning methods in fully competitive environments, large-scale continuous action space environments, and other environments with heterogeneous agents. Importantly, we also apply the mean field method in a ride-sharing problem using a real-world dataset. We propose a decentralized solution to this problem, which is more practical than existing centralized training methods.
翻译:多剂强化学习算法在大型环境中没有被广泛采用,许多代理商的规模往往与代理商的数量相比差强人意。使用平均的实地理论来综合代理商,已经作为解决这个问题的一种解决办法提出。然而,这个领域的几乎所有以往方法都为集中系统提供了强有力的假设,使环境所有代理商学习同样的政策,并且实际上彼此无法区分。在本文件中,我们放松了这种关于不可分的代理商的假设,并提出了一种被称为分散式的实用场游戏的新的中性实地系统,其中每个代理商可以与其他代理商相当不同。所有代理商都以分散式的方式学习独立政策,根据他们的当地观察,我们以分散式方式学习这个系统的理论性解决方案。我们为这个系统中基于Q学习的算法确定了一个固定点保证。我们的方法的一个实际结果是,我们可以解决经验领域中“奇肯和埃格”的问题,也就是说,使用分散式的实地学习方法,我们首先需要使用分散式学习方法,而与这个领域的共同基线相比,我们使用这个领域的通用的实地标准环境,我们提出一个更高的实地操作方法,我们不完全地学习一个实地方法,而不是实地学习。我们每个代理商。我们用一个实地方法来充分学习一个实地方法来充分学习。